Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (8): 2732-2740.doi: 10.13229/j.cnki.jdxbgxb.20240051
Text-based guided face image inpainting
Jing LIAN1( ),Ji-bao ZHANG1,Ji-zhao LIU2,Jia-jun ZHANG1,Zi-long DONG1
),Ji-bao ZHANG1,Ji-zhao LIU2,Jia-jun ZHANG1,Zi-long DONG1
- 1.School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730030,China
2.School of Information Science and Engineering,Lanzhou University,Lanzhou 730030,China
CLC Number:
- TP391
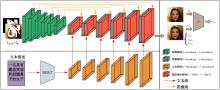
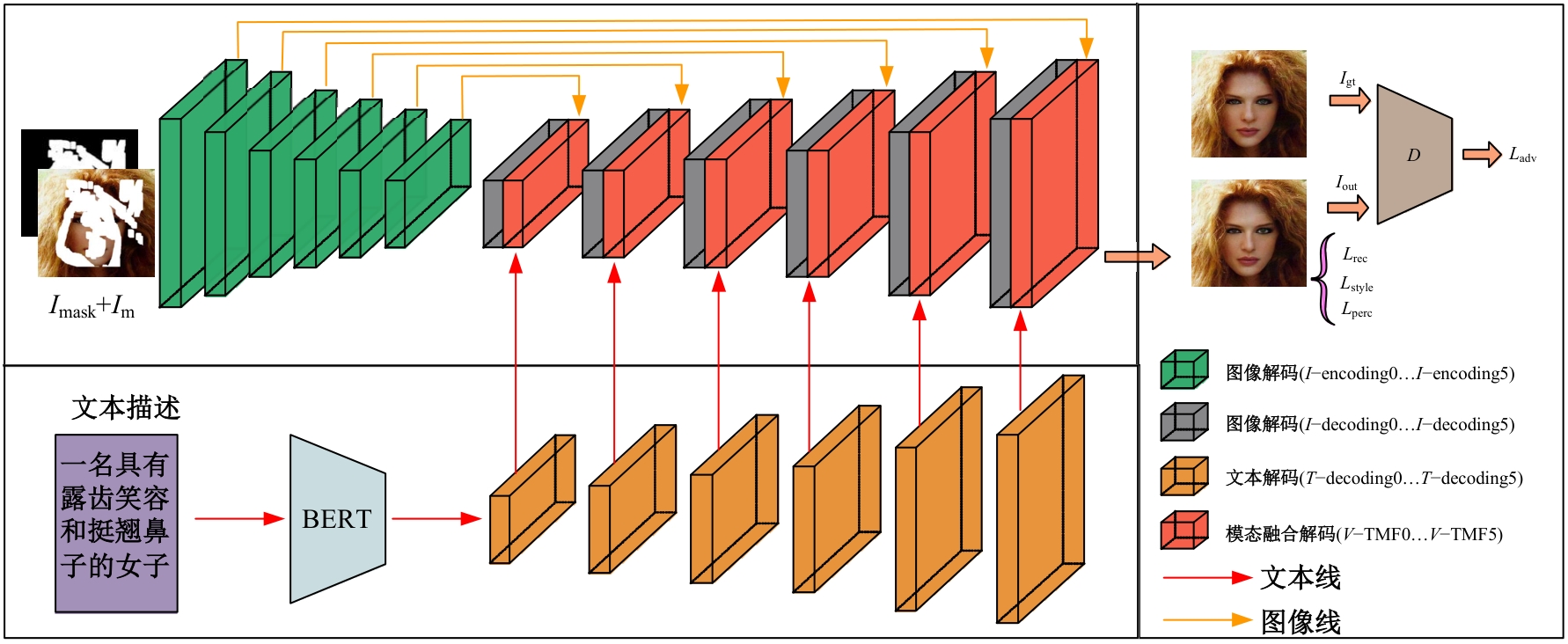
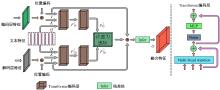
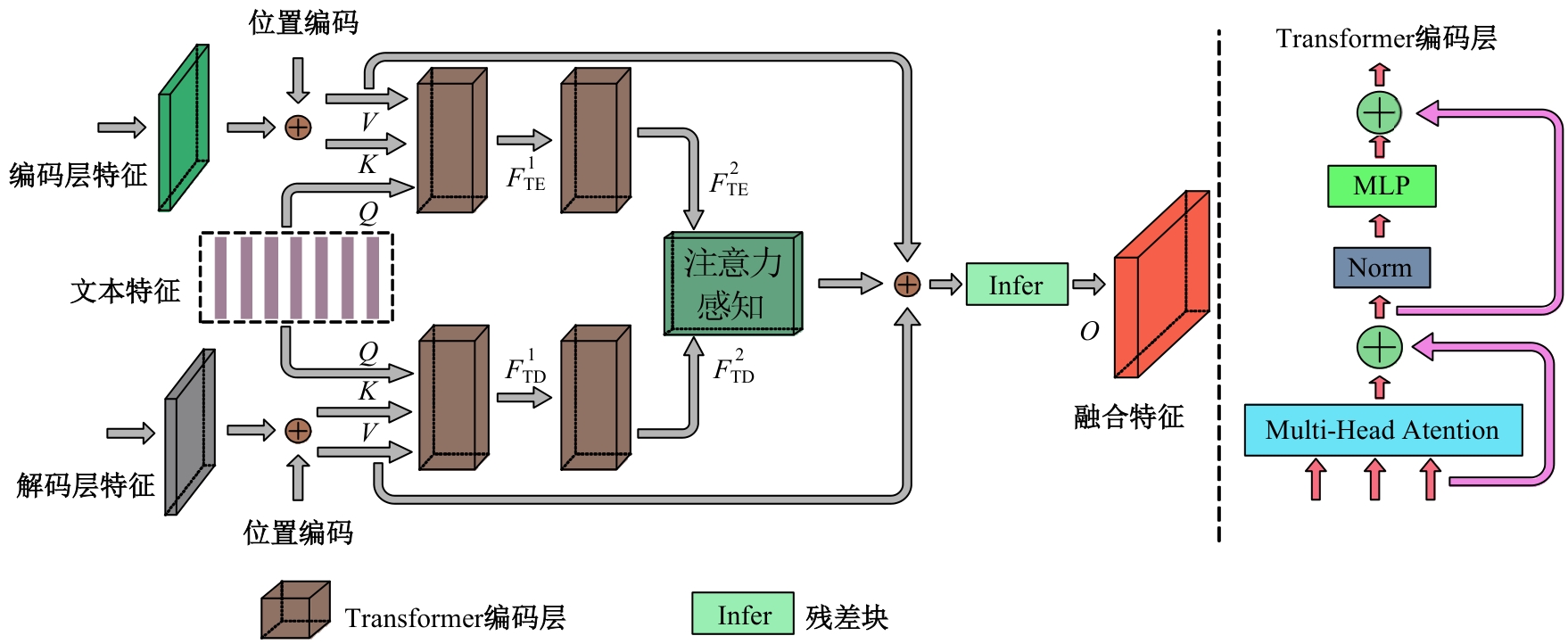




| [1] | 周大可, 张超, 杨欣. 基于多尺度特征融合及双重注意力机制的自监督三维人脸重建[J]. 吉林大学学报: 工学版, 2022, 52(10): 2428-2437. |
| Zhou Da-ke, Zhang Chao, Yang Xin.Self-supervised 3D face reconstruction based on multi-scale feature fusion and dual attention mechanism[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(10): 2428-2437. | |
| [2] | 王小玉, 胡鑫豪, 韩昌林. 基于生成对抗网络的人脸铅笔画算法[J].吉林大学学报: 工学版, 2021, 51(1): 285-292. |
| Wang Xiao-yu, Hu Xin-hao, Han Chang-lin. Face pencil drawing algorithms based on generative adversarial network[J]. Journal of Jilin University (Engineering and Technology Edition), 2021, 51(1): 285-292. | |
| [3] | Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: feature learning by inpainting[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2536-2544. |
| [4] | Iizuka S, Simo S E, Ishikawa H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics (ToG), 2017, 36(4): 1-14. |
| [5] | Yan Z, Li X, Li M, et al. Shift-net: image inpainting via deep feature rearrangement[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 1-17. |
| [6] | Liu H, Wan Z, Huang W, et al. Pd-gan: probabilistic diverse gan for image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 9371-9381. |
| [7] | Wan Z, Zhang J, Chen D, et al. High-fidelity pluralistic image completion with transformers[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, USA, 2021: 4692-4701. |
| [8] | Li W, Lin Z, Zhou K, et al. Mat: mask-aware transformer for large hole image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10758-10768. |
| [9] | Huang W, Deng Y, Hui S, et al. Sparse self-attention transformer for image inpainting[J]. Pattern Recognition, 2024, 145: 109897. |
| [10] | Lian J, Zhang J, Liu J, et al. Guiding image inpainting via structure and texture features with dual encoder[J]. The Visual Computer, 2024, 40: 4303-4317. |
| [11] | Devlin J, Chang M W, Lee K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[J/OL]. [2023-12-16]. arXiv preprint arXiv:. |
| [12] | Johnson J, Alahi A, Fei F L. Perceptual losses for real-time style transfer and super-resolution[C]∥14th European Conference, Amsterdam, The Netherlands, 2016: 694-711. |
| [13] | Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115: 211-252. |
| [14] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J/OL].[2023-12-17]. arXiv preprint arXiv:. |
| [15] | Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2794-2802. |
| [16] | Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2414-2423. |
| [17] | Liu G, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 85-100. |
| [18] | Li J, Wang N, Zhang L, et al. Recurrent feature reasoning for image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7760-7768. |
| [19] | Lugmayr A, Danelljan M, Romero A, et al. Repaint: inpainting using denoising diffusion probabilistic models[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11461-11471. |
| [20] | Chen L, Yuan C, Qin X, et al. Contrastive structure and texture fusion for image inpainting[J]. Neurocomputing, 2023, 536: 1-12. |
| [21] | Li A, Zhao L, Zuo Z, et al. MIGT: multi-modal image inpainting guided with text[J]. Neurocomputing, 2023, 520: 376-385. |
| [22] | Zhang L, Chen Q, Hu B, et al. Text-guided neural image inpainting[C]∥Proceedings of the 28th ACM International Conference on Multimedia, New York, USA, 2020: 1302-1310. |
| [1] | Yuan-ning LIU,Xing-zhe WANG,Zi-yu HUANG,Jia-chen ZHANG,Zhen LIU. Stomach cancer survival prediction model based on multimodal data fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2693-2702. |
| [2] | Jing-shu YUAN,Wu LI,Xing-yu ZHAO,Man YUAN. Semantic matching model based on BERTGAT-Contrastive [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2383-2392. |
| [3] | Hui-zhi XU,Dong-sheng HAO,Xiao-ting XU,Shi-sen JIANG. Expressway small object detection algorithm based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2003-2014. |
| [4] | Ru-bo ZHANG,Shi-qi CHANG,Tian-yi ZHANG. Review on image information hiding methods based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1497-1515. |
| [5] | Jian LI,Huan LIU,Yan-qiu LI,Hai-rui WANG,Lu GUAN,Chang-yi LIAO. Image recognition research on optimizing ResNet-18 model based on THGS algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1629-1637. |
| [6] | Bin WEN,Yi-fu DING,Chao YANG,Yan-jun SHEN,Hui LI. Self-selected architecture network for traffic sign classification [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1705-1713. |
| [7] | Zhen-jiang LI,Li WAN,Shi-rui ZHOU,Chu-qing TAO,Wei WEI. Dynamic estimation of operational risk of tunnel traffic flow based on spatial-temporal Transformer network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1336-1345. |
| [8] | Meng-xue ZHAO,Xiang-jiu CHE,Huan XU,Quan-le LIU. A method for generating proposals of medical image based on prior knowledge optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 722-730. |
| [9] | Hui-zhi XU,Shi-sen JIANG,Xiu-qing WANG,Shuang CHEN. Vehicle target detection and ranging in vehicle image based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 185-197. |
| [10] | Yuan-ning LIU,Zi-nan ZANG,Hao ZHANG,Zhen LIU. Deep learning-based method for ribonucleic acid secondary structure prediction [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 297-306. |
| [11] | Lei ZHANG,Jing JIAO,Bo-xin LI,Yan-jie ZHOU. Large capacity semi structured data extraction algorithm combining machine learning and deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(9): 2631-2637. |
| [12] | Lu Li,Jun-qi Song,Ming Zhu,He-qun Tan,Yu-fan Zhou,Chao-qi Sun,Cheng-yu Zhou. Object extraction of yellow catfish based on RGHS image enhancement and improved YOLOv5 network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(9): 2638-2645. |
| [13] | Xin-gang GUO,Ying-chen HE,Chao CHENG. Noise-resistant multistep image super resolution network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(7): 2063-2071. |
| [14] | Bai-you QIAO,Tong WU,Lu YANG,You-wen JIANG. A text sentiment analysis method based on BiGRU and capsule network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(7): 2026-2037. |
| [15] | Li-ping ZHANG,Bin-yu LIU,Song LI,Zhong-xiao HAO. Trajectory k nearest neighbor query method based on sparse multi-head attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1756-1766. |
|
||