吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (11): 3705-3714.doi: 10.13229/j.cnki.jdxbgxb.20240237
• 计算机科学与技术 • 上一篇
基于增强正例与层间负例的语义相似性模型
蔡晓东( ),黄业洋,董丽芳
),黄业洋,董丽芳
- 桂林电子科技大学 信息与通信学院,广西壮族自治区 桂林 541004
Semantic similarity model based on augmented positives and interlayer negatives
Xiao-Dong CAI(),Ye-yang HUANG,Li-fang DONG
- School of Information and Communication,Guilin University of Electronic Technology,Guilin 541004,China
摘要:
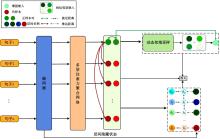
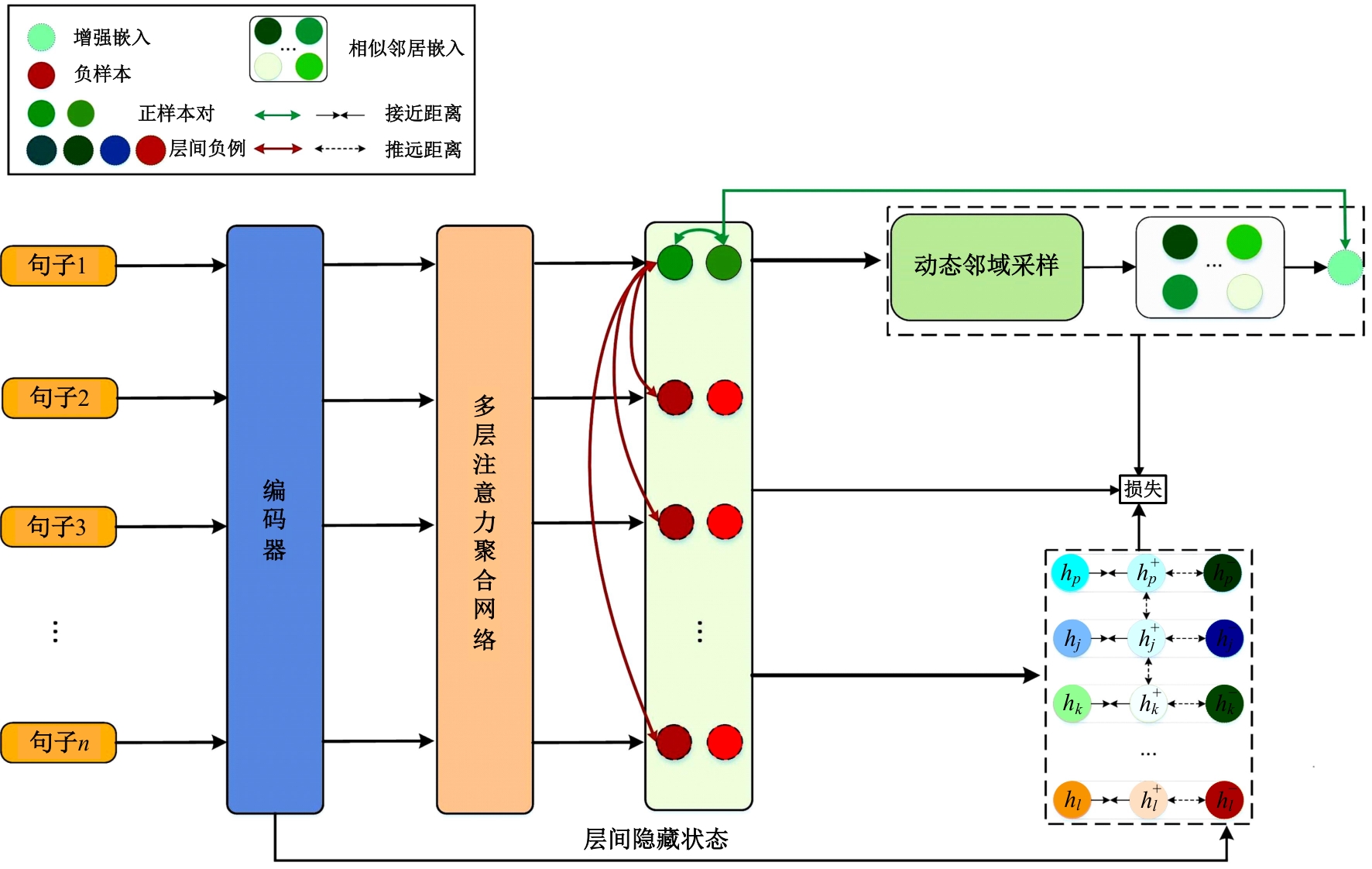
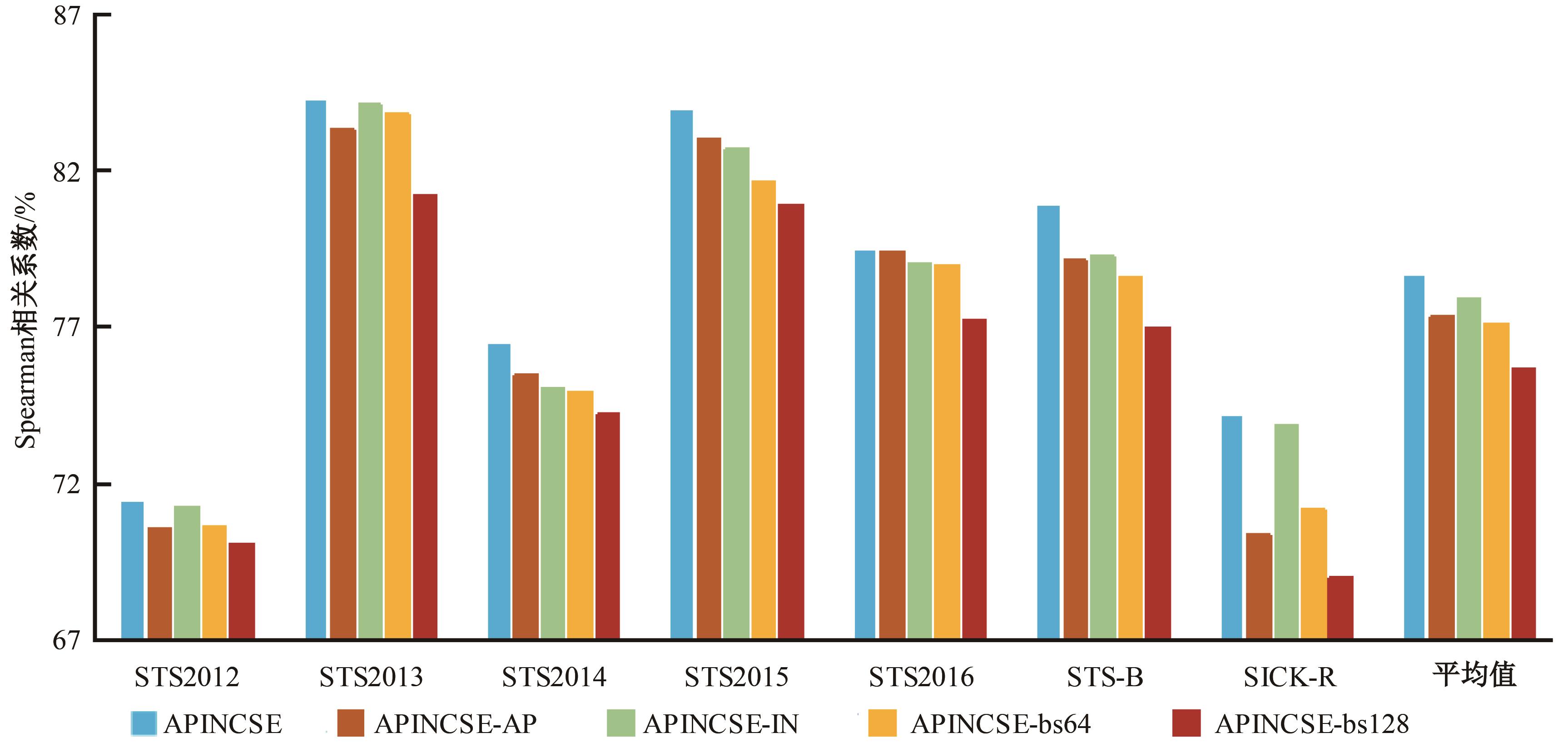
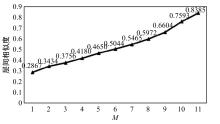
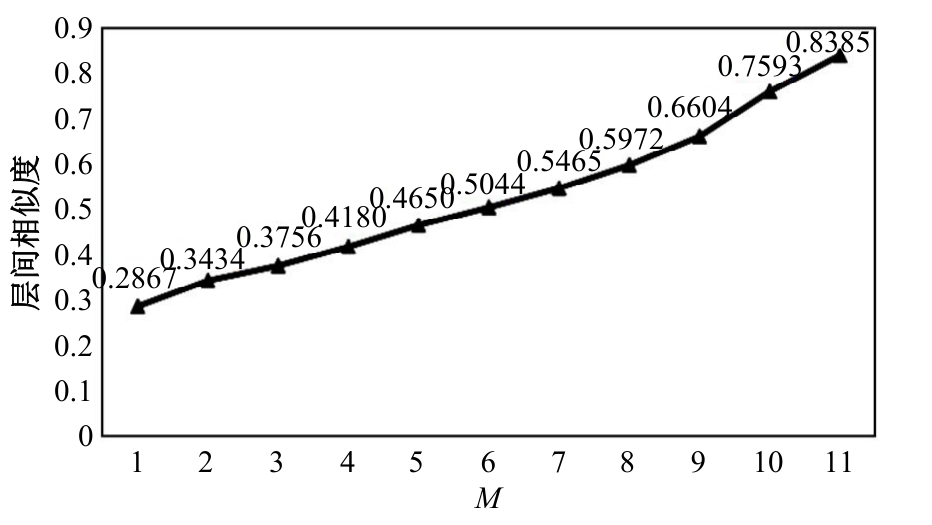
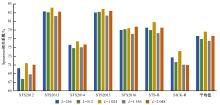
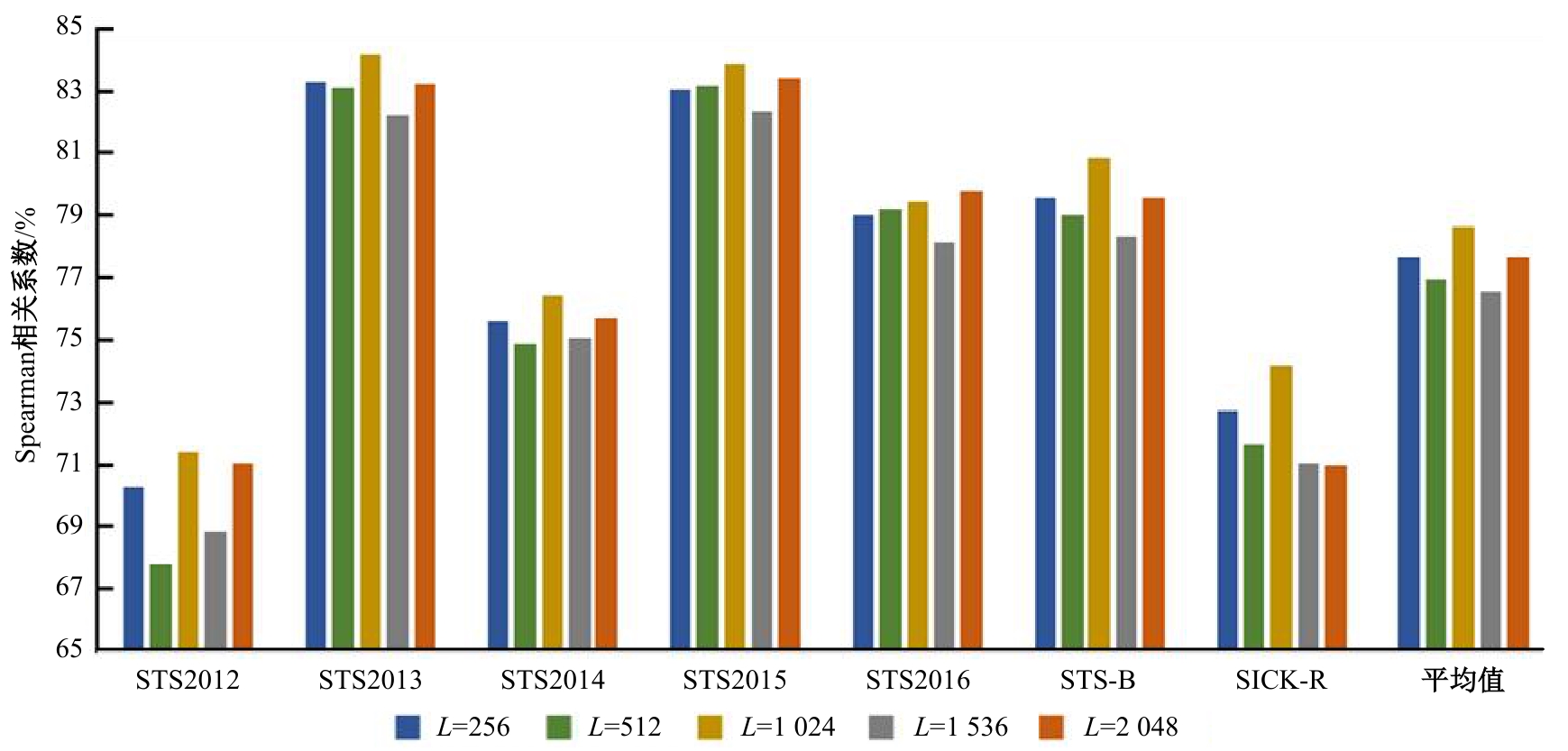
在基于对比学习的语义相似性模型中,不同正例句子间的信息交互不充分及传统的负样本采集策略中困难负例稀缺,导致模型难以捕捉句子间的细微特征差异,进而无法准确捕捉文本间的相似性。本文提出了一种基于增强正例与层间负例的语义相似性方法,通过设计动态邻域机制融合不同正例的信息,并提出了困难负例生成方法,显著提高了语义相似判断的相关性。首先,从动态邻域中检索与正例语义特征相似的句子嵌入,将其与正例拼接,并通过自注意力聚合得到增强正例,从而融合不同正例的信息;其次,提出了困难负例生成方法,将模型中间层的句子表示作为原始正例的困难负例,并引入交叉熵损失进行惩罚,以此改进负例采样策略。实验结果表明:在语义相似性任务数据集STS2012~STS2016、STS-B、SICK-R上,本文方法效果显著,Spearman相关系数较先进模型在BERT-base、BERT-large的基础上分别平均提升1.09和0.34个百分点。
中图分类号:
- TP391.1
| [1] | Cer D, Diab M, Agirre E, et al. SemEval-2017 task 1: semantic textual similarity multilingual and crosslingual focused evaluation[C]∥Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg, PA: ACL, 2017: 1-14. |
| [2] | Radford A, Narasimhar K. Improving language understanding by GenerativePre-Training[EB/OL].(2018-06-11)[2023-12-11].. |
| [3] | Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] ∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 4171-4186. |
| [4] | Liu Y H, Ott M, Goyal N, et al. RoBERTa: a robustly optimized BERT pretrainingapproach[EB/OL]. (2019-07-26)[2023-12-11].. |
| [5] | Yang Z L, Dai Z H, Yang Y M, et al. XLNet: generalized autogressive pretraining for language understanding[C] ∥Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2019: 5753-5763. |
| [6] | Li B H, Zhou H, et al. On the sentenceembeddings from pre-trained language models[C]∥Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020:9119-9130. |
| [7] | Reimers N, Gureuych, I. Sentence-BERT: sentence embeddings using siamese BERT-networks[C]∥Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3982-3992. |
| [8] | Gao T Y, Yao X C, Chen D Q. SimCSE: simple contrastive learning of sentence embeddings[C]∥Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 6894-6910. |
| [9] | Wu X, Gao C C, Zang L J, et al. ESimCSE: enhanced sample building method for contrastive learning of unsupervised sentence embedding[C]∥Proceedings of the 29th International Conference on Computational Linguistics. New York: ACM Press,2022:3898-3907. |
| [10] | Zhang Y H, Zhu H J, Wang Y L, et al. A contrastive framework for learning sentence representations from pairwise and triple-wise perspective in angular space[C]∥Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: CAL, 2022: 4892–4903. |
| [11] | Chuang Y S, Dangovski R, Luo H Y, et al. DiffCSE: difference-based contrastive learning for sentence embeddings[C]∥Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2023: 4207-4218. |
| [12] | Liu J D, Liu J H, Wang Q F, et al. RankCSE: unsupervised sentence representations learning via learning to rank[C]∥Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2023: 13785-13802. |
| [13] | Wang H, Li Y G, Huang Z, et al. SNCSE: contrastive learning for unsupervised sentence embedding with soft negative samples[C]∥International Conference on Intelligent Computing. New York, USA: ICIC, 2023: 419-431. |
| [14] | He H L, Zhang J L, Lan Z Z, et al.Instance smoothed contrastive learning for unsupervised sentence embedding[C]∥Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence. Washington, DC: AAAI Press, 2023: 12863-12871. |
| [15] | Robinson J, Chuang C Y, Sra S, et al. Contrastive learning with hard negative samples[C]∥9th International Conference on Learning Representations. Virtual, 2021: joshr17. |
| [16] | Wu X, Gao C C, Su Y P, et al.Smoothed contrastive learning for unsupervised sentence embedding[C]∥Proceedings of the 29th International Conference on Computational Linguistics. New York, USA: ICCL, 2022: 4902-4906. |
| [17] | Kim T, Yoo K M, Lee S G. Self-guided contrastive learning for BERT sentence representations[C]∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2021: 2528-2540. |
| [18] | Oh D, Kim Y J, Lee H D, et al.Don't judge a language model by its last layer: contrastive learning with layer-wise attention pooling[C]∥Proceedings of the 29th International Conference on Computational Linguistics. New York, USA: ICCL, 2022: 4585-4592. |
| [19] | Deng J H, Wan F Q, Yang T, et al. Clustering-aware negative sampling for unsupervised sentence representation[C] ∥Findings of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2023: 8713-8729. |
| [1] | 姚宗伟,陈辰,高振云,靳鸿鹏,荣浩,李学飞,黄虹溥,毕秋实. 基于合成图像数据集的挖掘机关键点识别[J]. 吉林大学学报(工学版), 2026, 56(1): 76-85. |
| [2] | 王琳虹,刘宇阳,刘子昱,鹿应佳,张宇恒,黄桂树. 基于YOLOv5的轻量化桥梁缺陷识别[J]. 吉林大学学报(工学版), 2025, 55(9): 2958-2968. |
| [3] | 廉敬,张继保,刘冀钊,张家骏,董子龙. 基于文本引导的人脸图像修复[J]. 吉林大学学报(工学版), 2025, 55(8): 2732-2740. |
| [4] | 刘元宁,王星喆,黄子彧,张家晨,刘震. 基于多模态数据融合的胃癌患者生存预测模型[J]. 吉林大学学报(工学版), 2025, 55(8): 2693-2702. |
| [5] | 李文辉,杨晨. 基于对比学习文本感知的小样本遥感图像分类[J]. 吉林大学学报(工学版), 2025, 55(7): 2393-2401. |
| [6] | 袁靖舒,李武,赵兴雨,袁满. 基于BERTGAT-Contrastive的语义匹配模型[J]. 吉林大学学报(工学版), 2025, 55(7): 2383-2392. |
| [7] | 徐慧智,郝东升,徐小婷,蒋时森. 基于深度学习的高速公路小目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2003-2014. |
| [8] | 张汝波,常世淇,张天一. 基于深度学习的图像信息隐藏方法综述[J]. 吉林大学学报(工学版), 2025, 55(5): 1497-1515. |
| [9] | 李健,刘欢,李艳秋,王海瑞,关路,廖昌义. 基于THGS算法优化ResNet-18模型的图像识别[J]. 吉林大学学报(工学版), 2025, 55(5): 1629-1637. |
| [10] | 文斌,丁弈夫,杨超,沈艳军,李辉. 基于自选择架构网络的交通标志分类算法[J]. 吉林大学学报(工学版), 2025, 55(5): 1705-1713. |
| [11] | 李振江,万利,周世睿,陶楚青,魏巍. 基于时空Transformer网络的隧道交通运行风险动态辨识方法[J]. 吉林大学学报(工学版), 2025, 55(4): 1336-1345. |
| [12] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [13] | 金虎,申玉生,方勇,于丽,周佳媚. 基于深度学习SSD算法的公路隧道衬砌细小裂缝识别[J]. 吉林大学学报(工学版), 2025, 55(11): 3653-3659. |
| [14] | 姜来为,王策,杨宏宇. 基于深度学习的多目标跟踪研究进展综述[J]. 吉林大学学报(工学版), 2025, 55(11): 3429-3445. |
| [15] | 刘元宁,臧子楠,张浩,刘震. 基于深度学习的核糖核酸二级结构预测方法[J]. 吉林大学学报(工学版), 2025, 55(1): 297-306. |
|
||