吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (10): 3283-3295.doi: 10.13229/j.cnki.jdxbgxb.20240086
• 计算机科学与技术 • 上一篇
基于图结构引导和位置信息强化的人体姿态估计
关欣( ),周子健,李锵()
),周子健,李锵()
- 天津大学 微电子学院,天津 300072
Human pose estimation based on graph structure guidance and location information enhancement
Xin GUAN(),Zi-jian ZHOU,Qiang LI()
- School of Microelectronics,Tianjin University,Tianjin 300072,China
摘要:
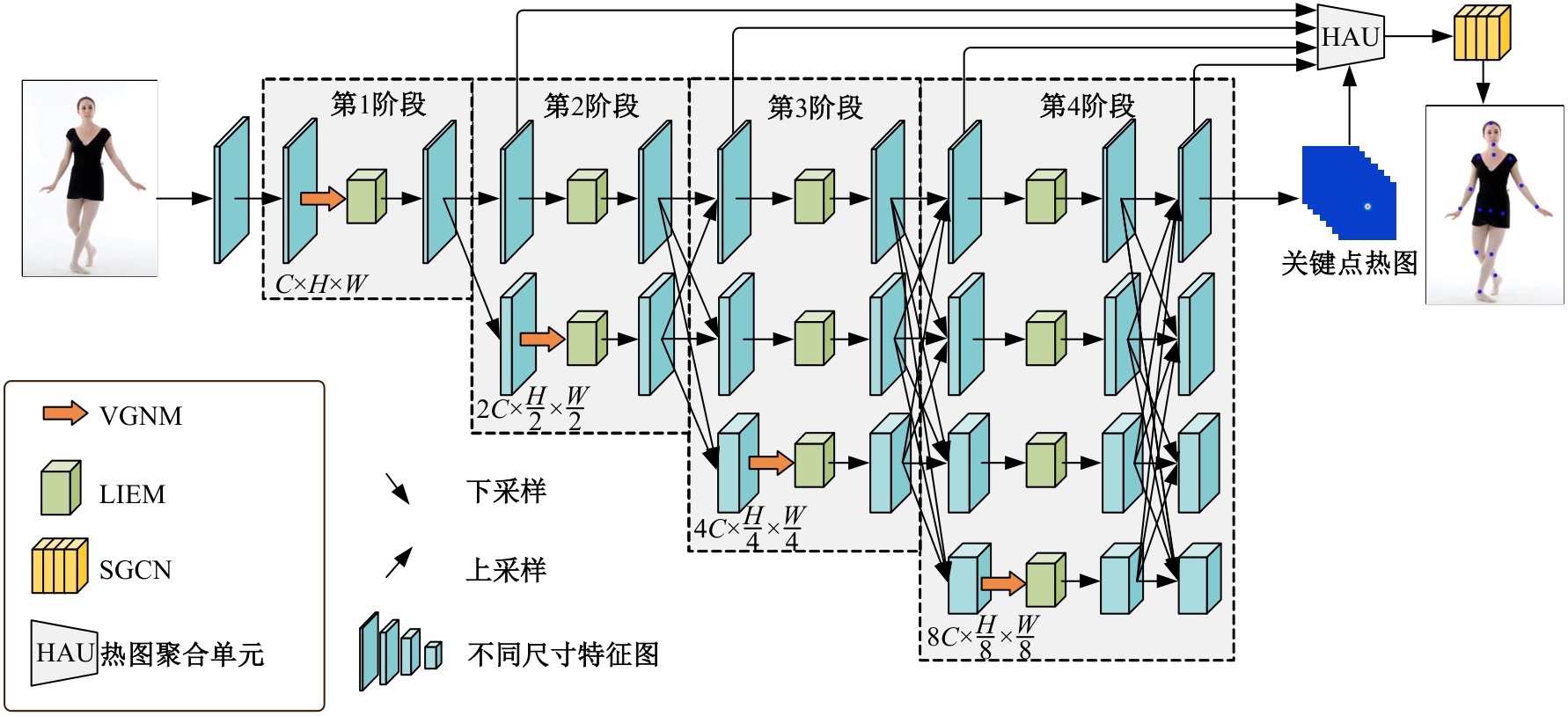
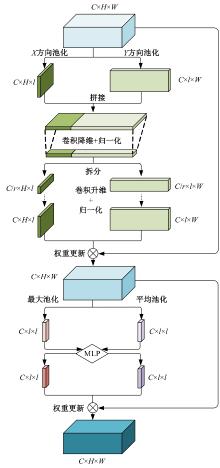
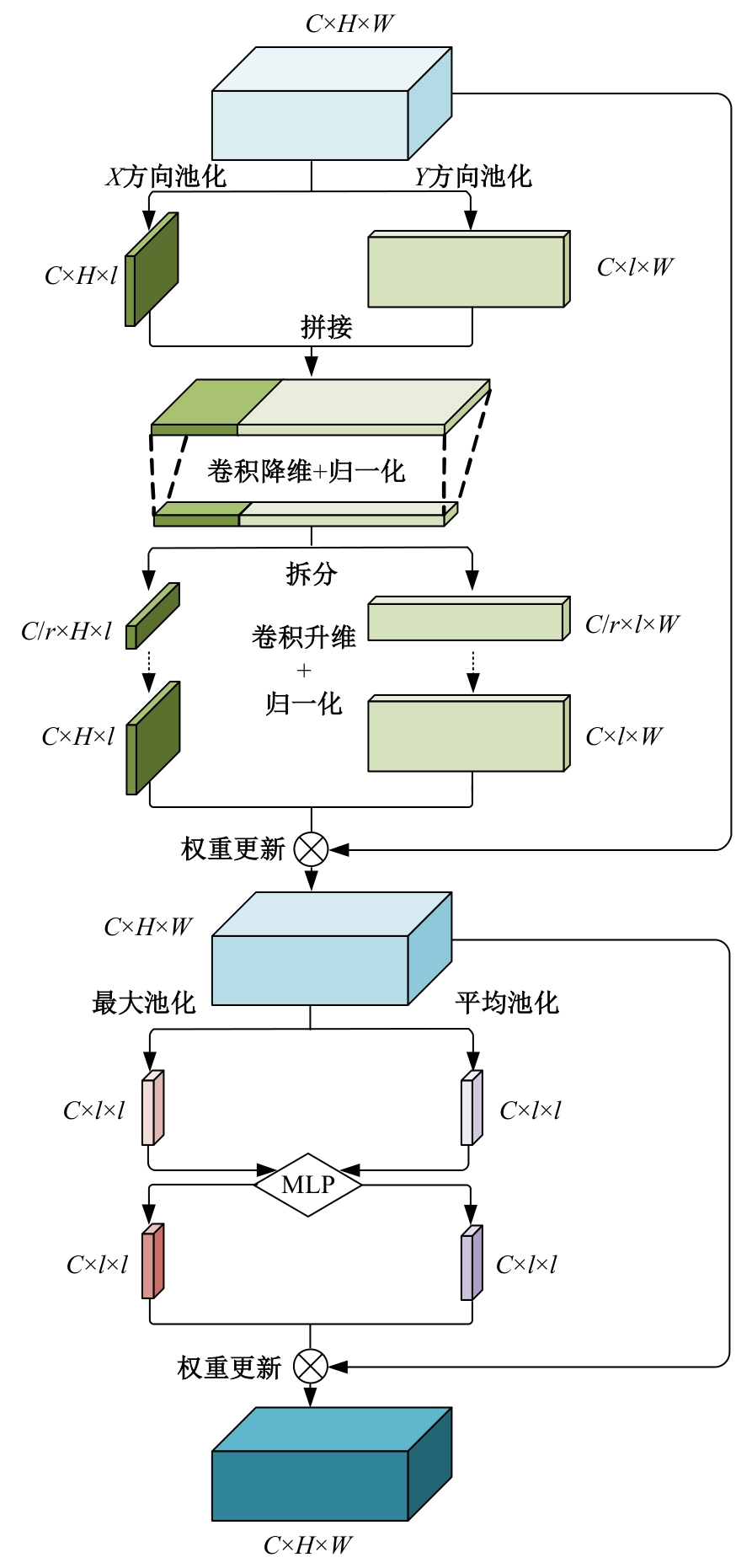
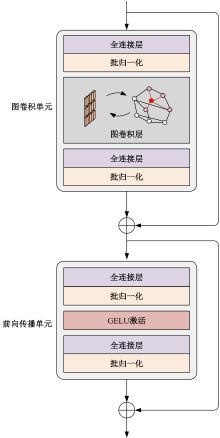
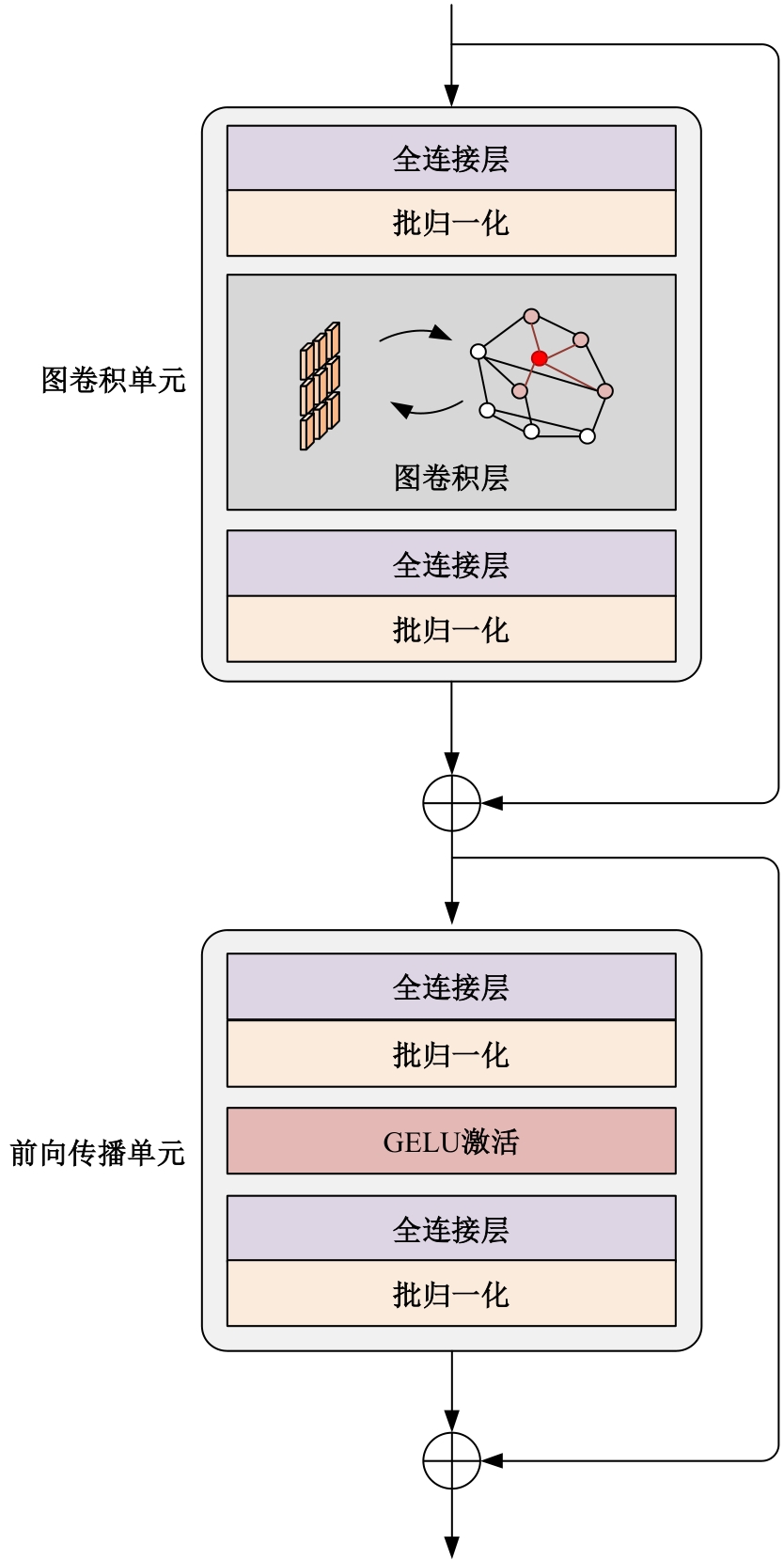
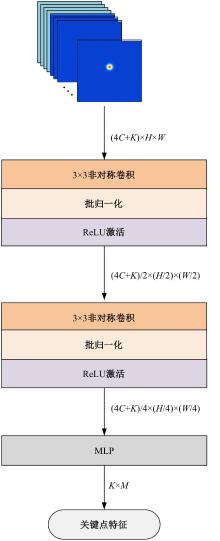
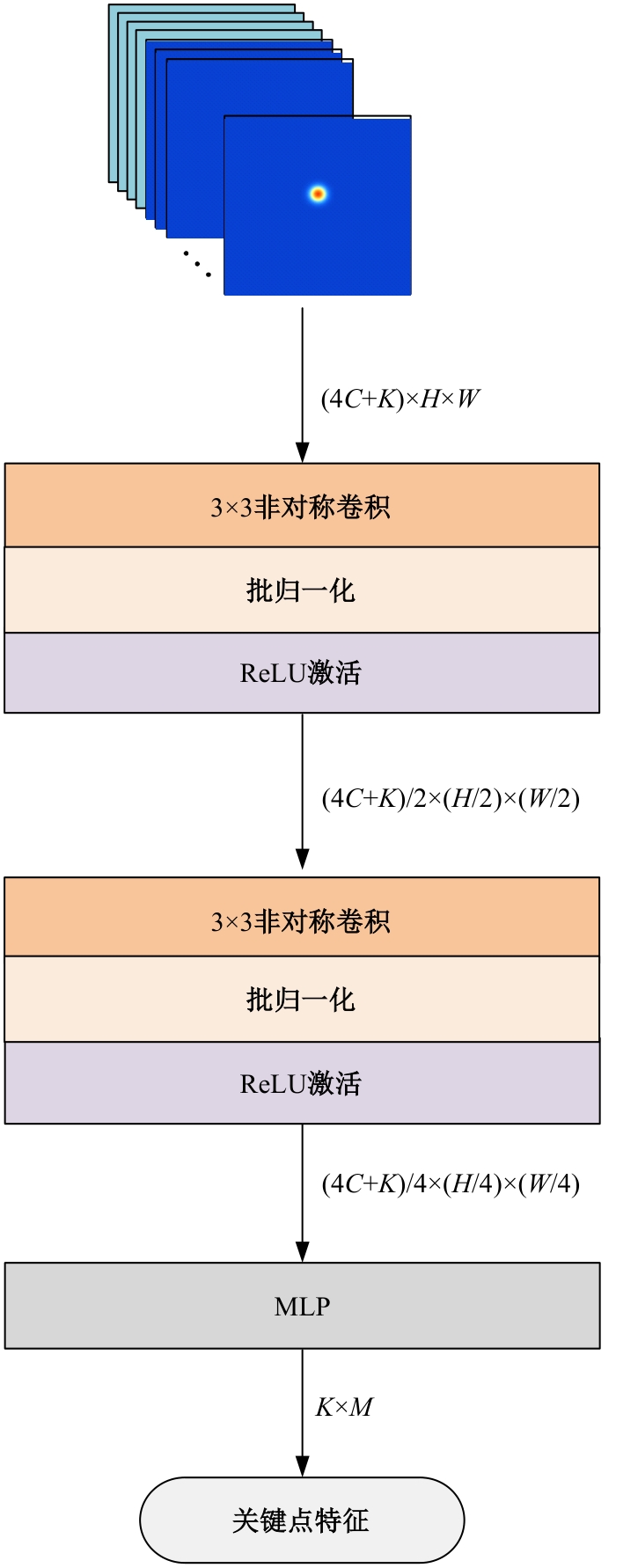
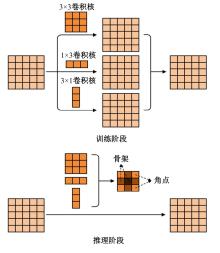
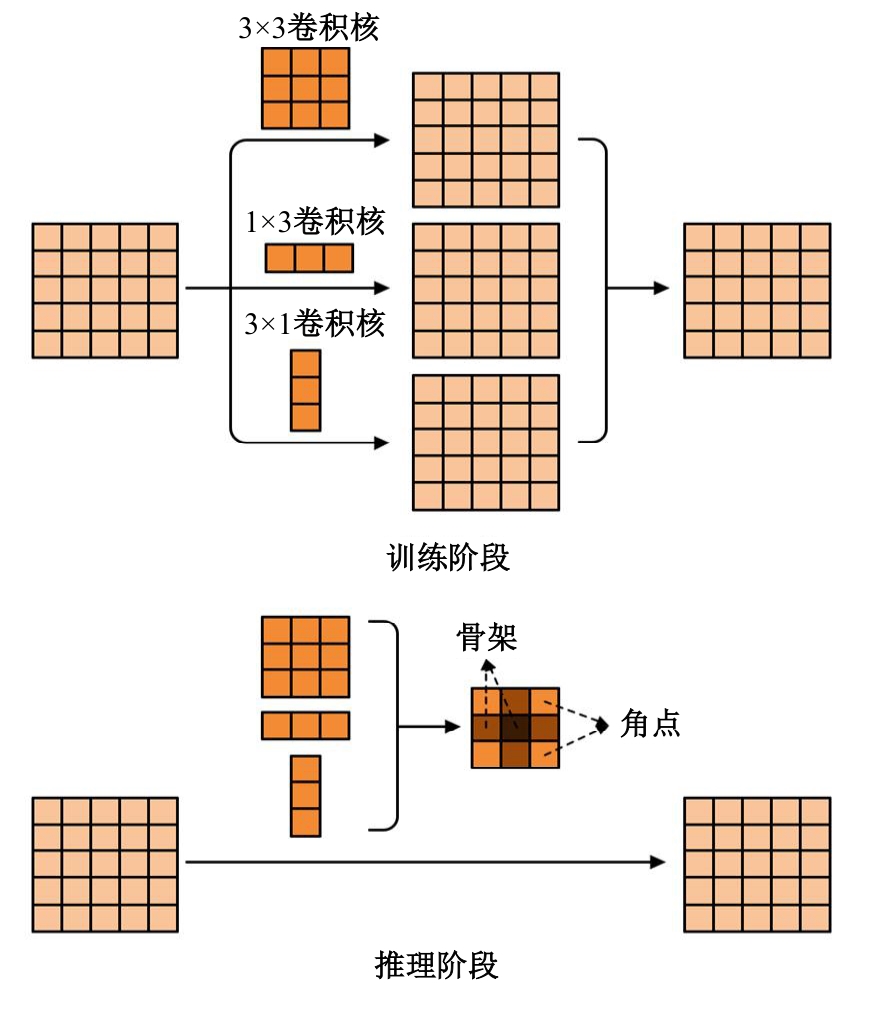
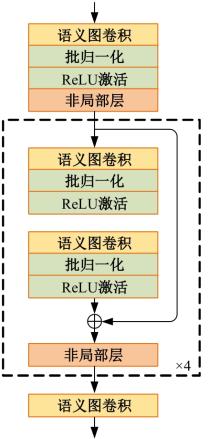
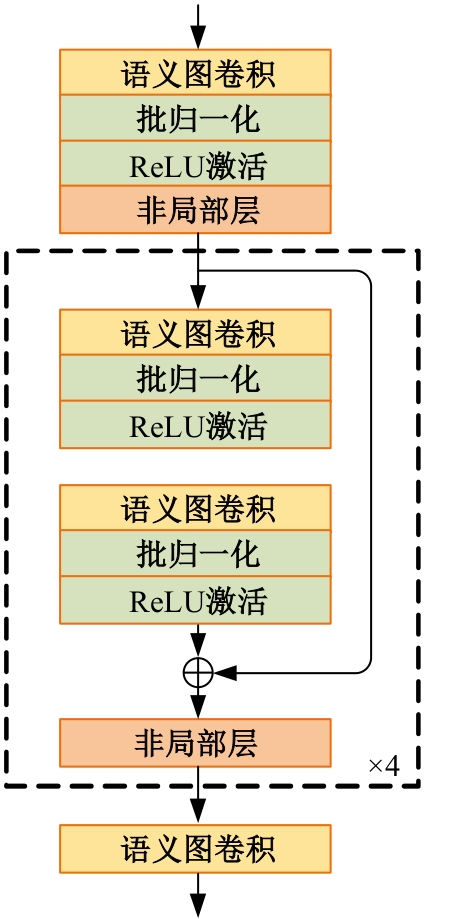
高自由度的肢体常构成各种复杂的姿态,极易产生关键点被遮挡的现象,定位遮挡关键点是人体姿态估计的难点之一,针对上述难点,提出了一种图结构引导并强化关键点位置信息的人体姿态估计方法。首先该方法在高分辨率网络中融入位置信息强化模块,用于提升可见关键点空间位置信息的表征精度。然后,在主干网络并行支路中引入视觉图神经模块,引导网络提取包含人体关键点的相关特征,在像素坐标空间中挖掘关键点之间局部和全局的拓扑连接关系,以便推测被遮挡关键点的位置信息。最后,结合关键点热图聚合单元和语义图卷积网络,在语义空间中更新各关键点间的亲和力权重,表示躯干结构约束下关键点之间的拓扑依赖关系,进一步优化被遮挡关键点的估计。本文模型在COCO2017测试集上的平均精度达到78.1%,能够精准估计复杂姿态中易被遮挡的关键点。
中图分类号:
- TP391.4




| [1] | Eduardo RDS, Adams LS, Stoffel R A, et al. Monocular multi-person pose estimation: a survey[J]. Pattern Recognition, 2021, 118: No.108046. |
| [2] | 田皓宇, 马昕, 李贻斌. 基于骨架信息的异常步 态识别方法[J]. 吉林大学学报: 工学版, 2022, 52(4): 725-737. |
| Tian Hao-yu, Ma Xin, Li Yi-bin. Abnormal gait recognition method based on skeleton information[J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(4): 725-737. | |
| [3] | Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [4] | Toshev A, Szegedy C. DeepPose: Human pose estimation via deep neural networks[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1653-1660. |
| [5] | Tompson J, Jain A, Lecun Y, et al. Joint training of a convolutional network and a graphical model for human pose estimation[C]∥Neural Information Processing Systems,Montreal, Canada, 2014: 1799-1807. |
| [6] | Newell A, Yang K, Deng J. Stacked hourglass networks for human pose estimation[C]∥European Conference on Computer Vision, Amsterdam, Netherlands, 2016: 483-499. |
| [7] | Chen Y L, Wang Z C, Peng Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7103-7112. |
| [8] | Xiao B, Wu H P, Wei Y C. Simple baselines for human pose estimation and tracking[C]∥European Conference on Computer Vision, Munich, Germany, 2018: 472-487. |
| [9] | Sun K, Xiao B, Liu D, et al. Deep high-resolution representation learning for human pose estimation [C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5686-5796. |
| [10] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]∥Neural Information Processing Systems(NeurIPS),Long Beach, USA, 2017: 5998-6008. |
| [11] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale[C]∥International Conference on Learning Representations, Online, 2021. |
| [12] | Li Y J, Zhang S K, Wang Z C, et al. Tokenpose: Learning keypoint tokens for human pose estimation[C]∥Proceedings of the IEEE International Conference on Computer Vision(ICCV),Montreal, Canda, 2021: 11293-11302. |
| [13] | Yuan Y H, Fu R, Huang L, et al. Hrformer: high-resolution transformer for dense prediction[J]. Advances in Neural Information Processing Systems, 2021, 34: 7281-7293. |
| [14] | Yang S, Quan Z B, Nie M, et al. Transpose: Keypoint localization via transformer[C]∥Proceedings of the IEEE International Conference on Computer Vision, Montreal, Canda, 2021: 11782-11792. |
| [15] | Li G H, Müller M, Thabet A, et al. DeepGCNs: Can GCNs Go As Deep As CNNs?[C]∥IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 9266-9275. |
| [16] | Qiu L T, Zhang X Y Y, Li Y R, et al. Peeking into occluded joints: A novel framework for crowd pose estimation[C]∥European Conference on Computer Vision, Glasgow, UK, 2020: 488-504. |
| [17] | Bin Y R, Chen Z M, Wei X S, et al. Structure-aware human pose estimation with graph convolutional networks[J]. Pattern Recognition, 2020, 106: No.107410. |
| [18] | Wang J, Long X, Gao Y, et al. Graph-PCNN: Two stage human pose estimation with graph pose refinement[C]∥European Conference on Computer Vision, Glasgow, UK, 2020: 492-508. |
| [19] | Banik S, GarcÍa A M, Knoll A. 3D human pose regression using graph convolutional network[C]∥IEEE International Conference on Image Processing(ICIP), Anchorage, USA, 2021: 924-928. |
| [20] | Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Nashville, USA, 2021: 13708-13717. |
| [21] | Han K, Wang Y H, Guo J Y, et al. Vision gnn: An image is worth graph of nodes[J]. Advances in Neural Information Processing Systems, 2022, 35: 8291-8303. |
| [22] | Huang G, Liu Z, Laurens V D M, et al. Densely connected convolutional networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, USA, 2017: 4700-4708. |
| [23] | Ding X H, Guo Y C, Ding G G, et al. ACNet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks[C]∥International Conference on Computer Vision, Seoul, South Korea, 2019: 1911-1920. |
| [24] | Zhao L, Peng X, Tian Y, et al. Semantic graph convolutional networks for 3D Human Pose Regression[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3420-3430. |
| [25] | Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, USA, 2018: 7794-7803. |
| [26] | Yang J W, Lu J S, Lee S, et al. Graph R-CNN for scene graph generation[C]∥European Conference on Computer Vision, Munich, Germany, 2018: 690-706. |
| [27] | Velikovi P, Cucurull G, Casanova A, et al. Graph attention networks[J]. Stat, 2017, 1050(20): No.10-48550. |
| [28] | Andriluka M, Pishchulin L, Gehler P, et al. 2D human pose estimation: New benchmark and state of the art analysis[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 3686-3693. |
| [29] | Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: Common objects in context[C]∥Proceedings of the European Conference on Computer Vision(ECCV), Zurich, the Switzerland, 2014: 740-755. |
| [30] | Zhang K, He P, Yao P, et al. Learning enhanced resolution-wise features for human pose estimation[C]∥IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 2020: 2256-2260. |
| [31] | Wang R, Wu W Y, Wang X Y. Enhancing multi-scale information exchange and feature fusion for human pose estimation[J]. The Visual Computer, 2023, 39(10): 4751-4765. |
| [32] | Tran T D, Vo X T, Nguyen D L, et al. High-resolution network with attention module for human pose estimation[C]∥Asian Control Conference, Jeju Island, South Korea, 2022: 459-464. |
| [33] | Dong K W, Sun Y J, Cheng X Z, et al. Combining detailed appearance and multi-scale representation: A structure-context complementary network for human pose estimation[J]. Applied Intelligence, 2023, 53(7): 8097-8113. |
| [34] | Soomro K, Zamir A R, Shah M. UCF101: a dataset of 101 human actions classes from videos in the wild[J/OL].[2023-08-16]. . |
| [1] | 姚宗伟,陈辰,高振云,靳鸿鹏,荣浩,李学飞,黄虹溥,毕秋实. 基于合成图像数据集的挖掘机关键点识别[J]. 吉林大学学报(工学版), 2026, 56(1): 76-85. |
| [2] | 侯越,张鑫,武月. 基于时空动态约束图反馈的交通流预测[J]. 吉林大学学报(工学版), 2026, 56(1): 183-198. |
| [3] | 李家宝,王成军,苏文杭. 基于自适应参数化非极大值抑制的二维人体姿态估计算法[J]. 吉林大学学报(工学版), 2025, 55(7): 2425-2433. |
| [4] | 侯越,郭劲松,林伟,张迪,武月,张鑫. 分割可跨越车道分界线的多视角视频车速提取方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1692-1704. |
| [5] | 刘广文,赵绮莹,王超,高连宇,才华,付强. 基于渐进递归的生成对抗单幅图像去雨算法[J]. 吉林大学学报(工学版), 2025, 55(4): 1363-1373. |
| [6] | 才华,朱瑞昆,付强,王伟刚,马智勇,孙俊喜. 基于隐式关键点互联的人体姿态估计矫正器算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1061-1071. |
| [7] | 程德强,刘规,寇旗旗,张剑英,江鹤. 基于自适应大核注意力的轻量级图像超分辨率网络[J]. 吉林大学学报(工学版), 2025, 55(3): 1015-1027. |
| [8] | 刘广文,谢欣月,付强,才华,王伟刚,马智勇. 基于时空模板焦点注意的Transformer目标跟踪算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1037-1049. |
| [9] | 才华,郑延阳,付强,王晟宇,王伟刚,马智勇. 基于多尺度候选融合与优化的三维目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(2): 709-721. |
| [10] | 姜来为,王策,杨宏宇. 基于深度学习的多目标跟踪研究进展综述[J]. 吉林大学学报(工学版), 2025, 55(11): 3429-3445. |
| [11] | 朱圣杰,王宣,徐芳,彭佳琦,王远超. 机载广域遥感图像的尺度归一化目标检测方法[J]. 吉林大学学报(工学版), 2024, 54(8): 2329-2337. |
| [12] | 才华,寇婷婷,杨依宁,马智勇,王伟刚,孙俊喜. 基于轨迹优化的三维车辆多目标跟踪[J]. 吉林大学学报(工学版), 2024, 54(8): 2338-2347. |
| [13] | 赖丹晖,罗伟峰,袁旭东,邱子良. 复杂环境下多模态手势关键点特征提取算法[J]. 吉林大学学报(工学版), 2024, 54(8): 2288-2294. |
| [14] | 井佩光,田雨豆,汪少初,李云,苏育挺. 基于动态扩散图卷积的交通流量预测算法[J]. 吉林大学学报(工学版), 2024, 54(6): 1582-1592. |
| [15] | 孙铭会,薛浩,金玉波,曲卫东,秦贵和. 联合时空注意力的视频显著性预测[J]. 吉林大学学报(工学版), 2024, 54(6): 1767-1776. |
|
||