Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (10): 3169-3179.doi: 10.13229/j.cnki.jdxbgxb.20231428
Autonomous driving policy based on reinforcement learning with environment representation
Yu-tao LUO1,2( ),Zhi-cheng XUE1,2
),Zhi-cheng XUE1,2
- 1.School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou 510640,China
2.Guangdong Provincial Key Laboratory of Automotive Engineering,Guangzhou 510640,China
CLC Number:
- U463.6
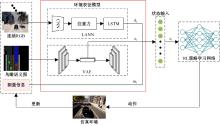
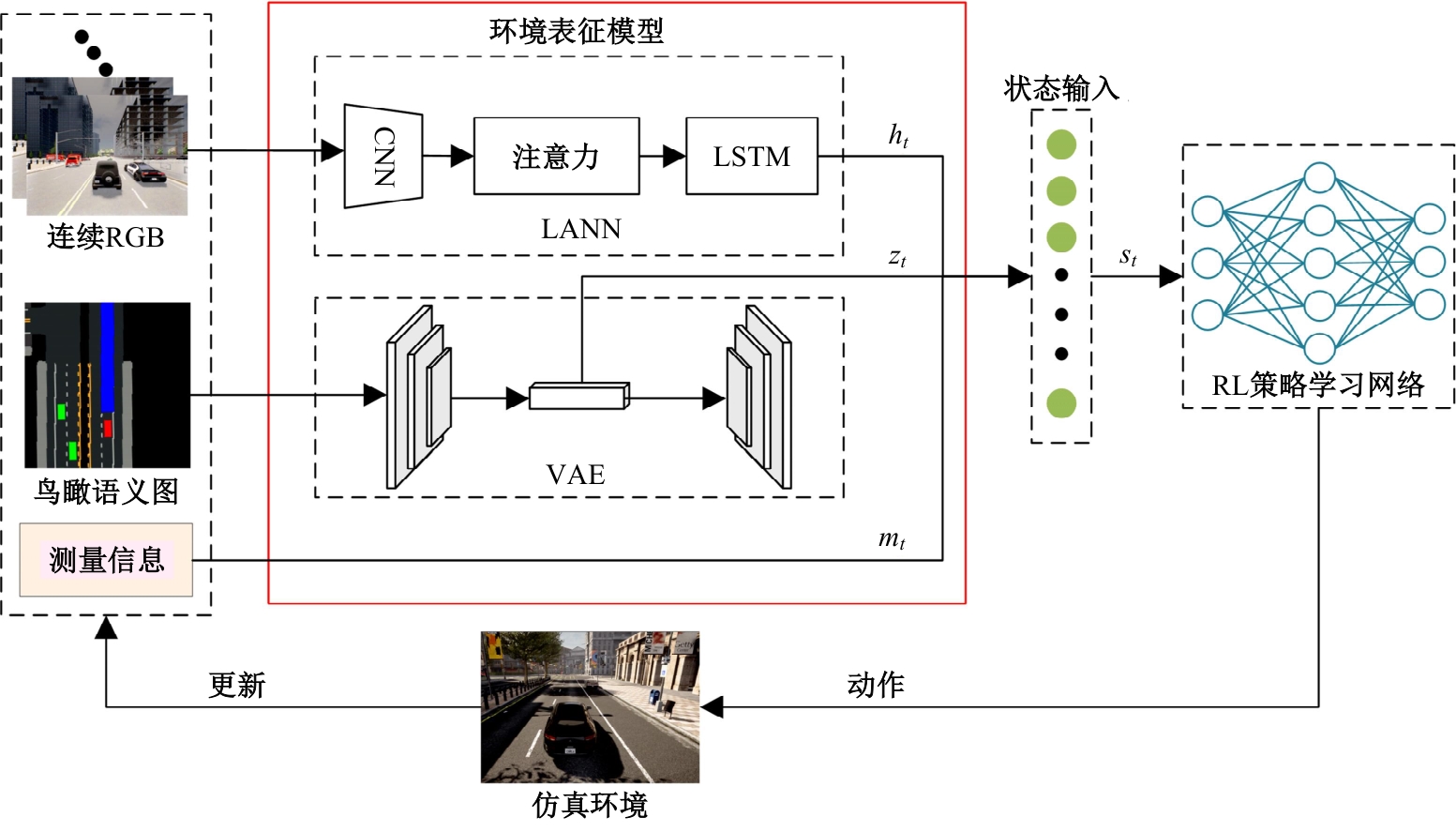
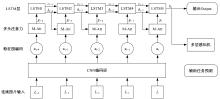
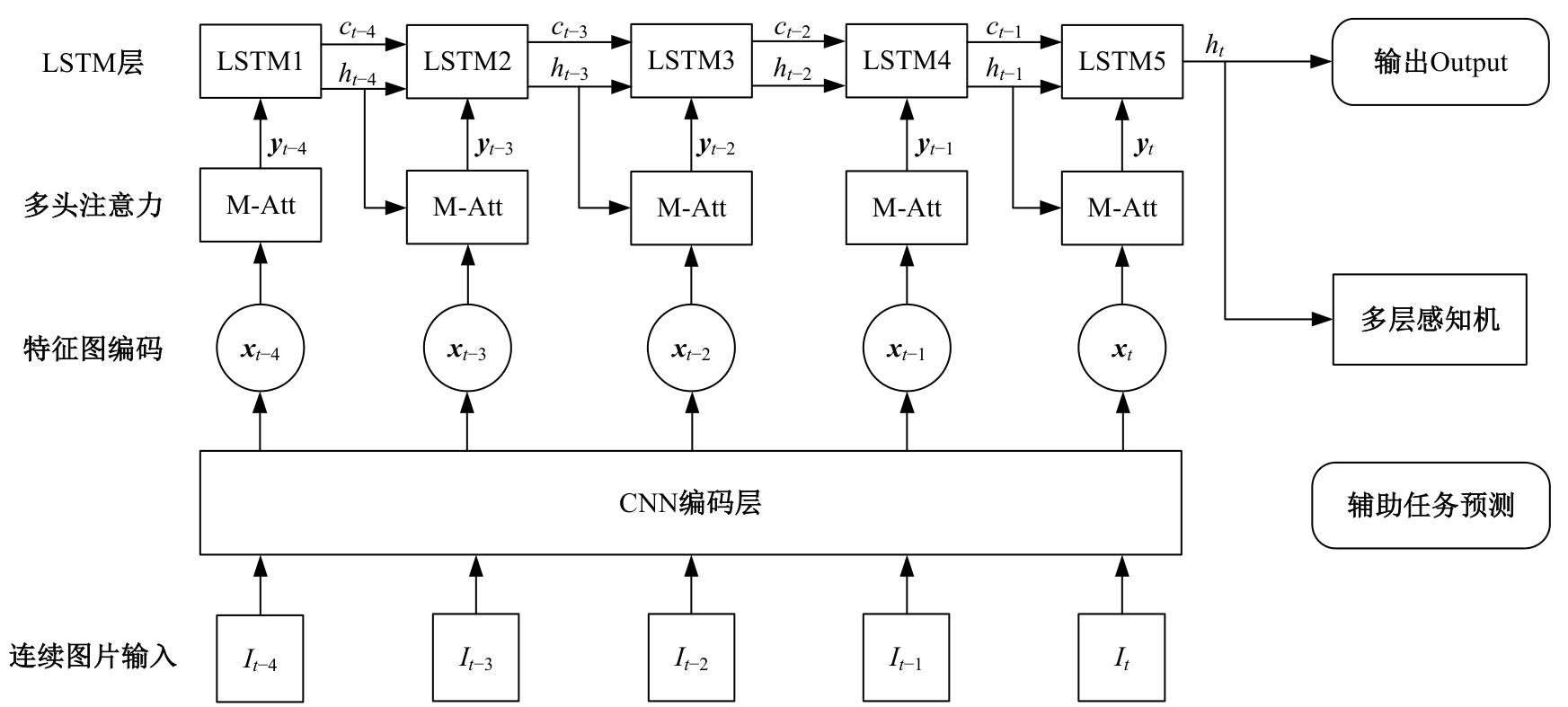
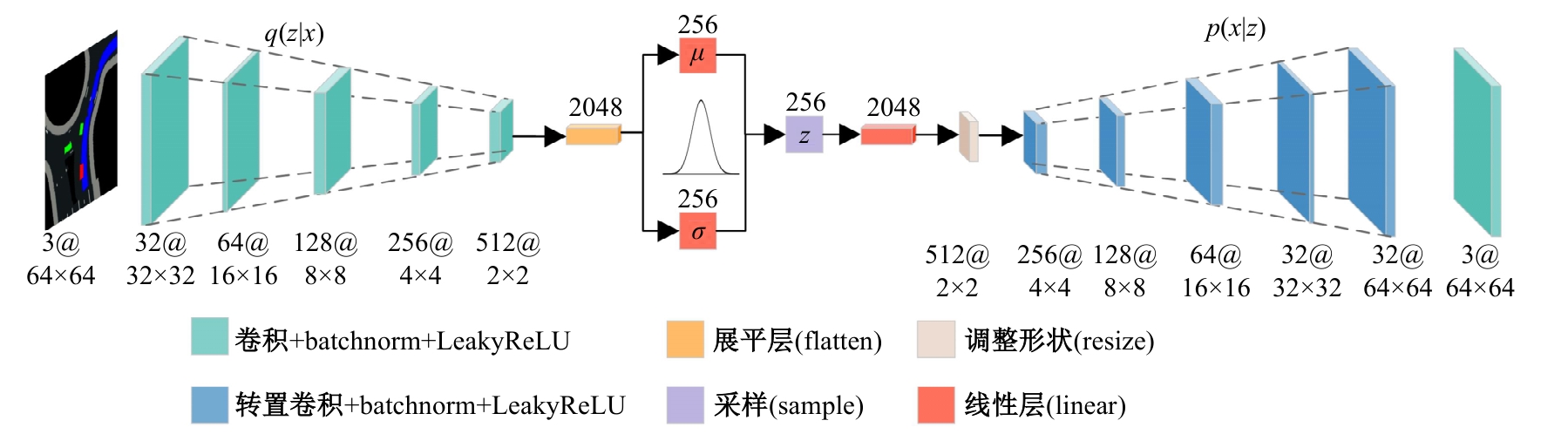
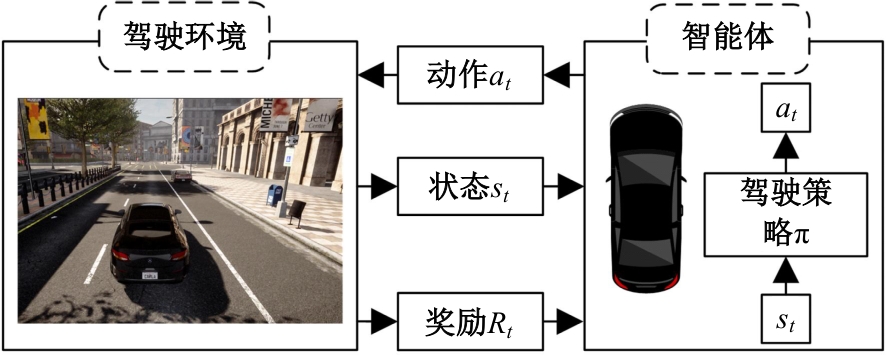
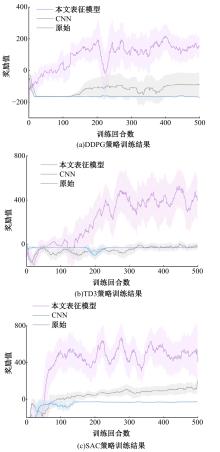
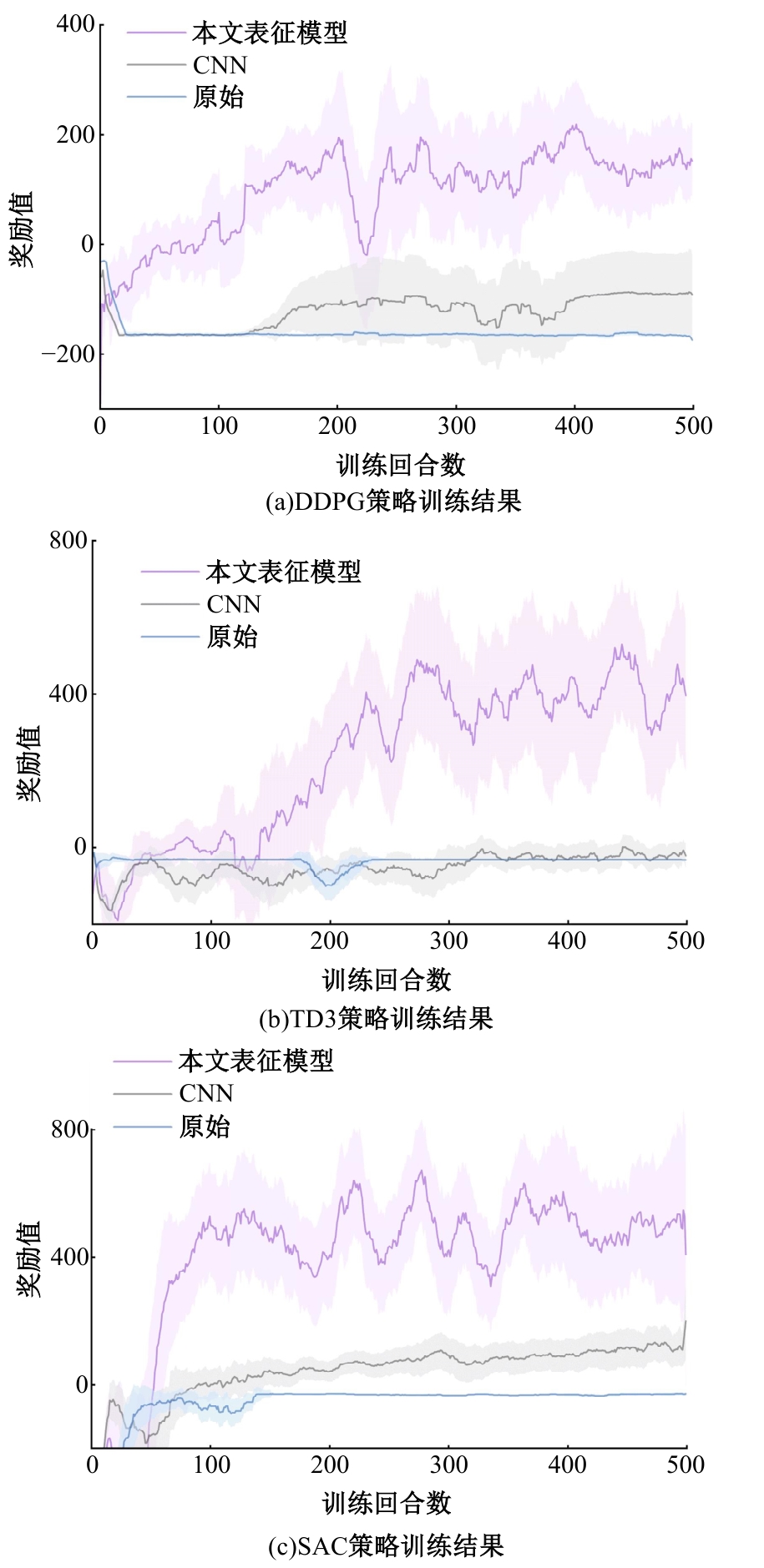
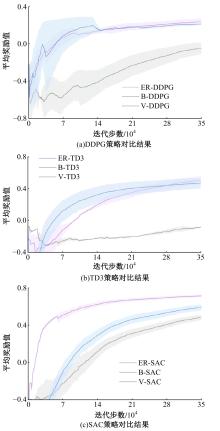
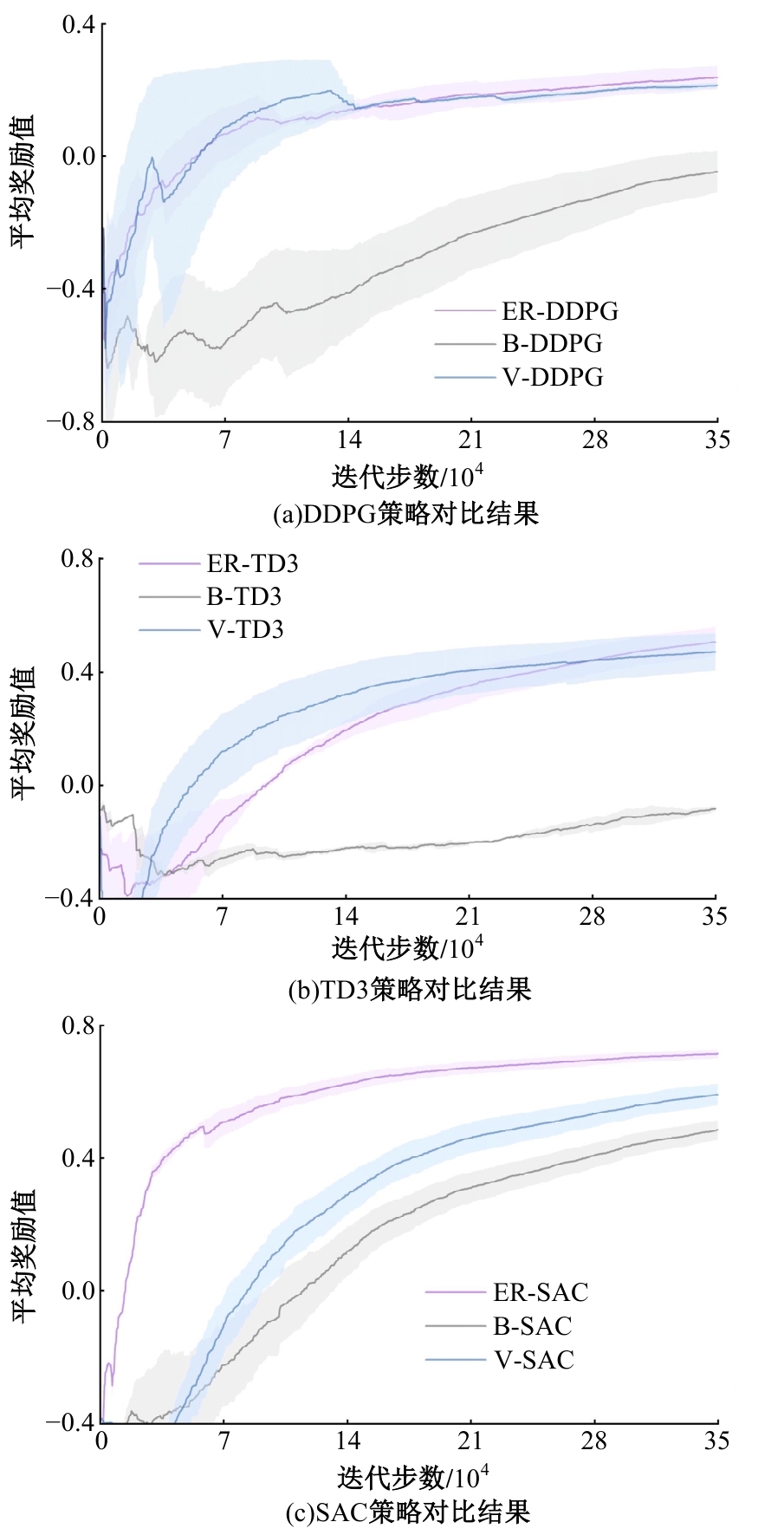

| [1] | Elallid B B, Benamar N, Hafid A S, et al. A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving[J]. Journal of King Saud University-Computer and Information Sciences, 2022, 34(9): 7366-7390. |
| [2] | Aradi S. Survey of deep reinforcement learning for motion planning of autonomous vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 23(2): 740-759. |
| [3] | Kendall A, Hawke J, Janz D, et al. Learning to drive in a day[C]∥International Conference on Robotics and Automation(ICRA), Piscataway, USA, 2019: 8248-8254. |
| [4] | Dosovitskiy A, Ros G, Codevilla F, et al. CARLA: An open urban driving simulator[C]∥Proceedings of the 1st Annual Conference on Robot Learning,New York, USA, 2017: 1-16. |
| [5] | 杨顺, 蒋渊德, 吴坚, 等. 基于多类型传感数据的自动驾驶深度强化学习方法[J]. 吉林大学学报:工学版, 2019, 49(4): 1026-1033. |
| Yang Shun, Jiang Yuan-de, Wu Jian, et al. Autonomous driving policy learning based on deep reinforcement learning and multi-type sensor data[J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(4): 1026-1033. | |
| [6] | 陈鑫, 兰凤崇, 陈吉清. 基于改进深度强化学习的自动泊车路径规划[J]. 重庆理工大学学报:自然科学版, 2021, 35(7): 17-27. |
| Chen Xin, Lan Feng-chong, Chen Ji-qing. Deep reinforcement learning based trajectory planning for automatic parking[J]. Journal of Chongqing University of Technology(Natural Science Edition), 2021, 35(7): 17-27. | |
| [7] | Chen J, Yuan B, Tomizuka M. Model-free deep reinforcement learning for urban autonomous driving[C]∥IEEE Intelligent Transportation Systems Conference(ITSC), Piscataway,USA, 2019: 2765-2771. |
| [8] | Wu K Y, Wang H, Esfahani M A, et al. Learn to navigate autonomously through deep reinforcement learning[J]. IEEE Transactions on Industrial Electronics, 2021, 69(5): 5342-5352. |
| [9] | Liang X D, Wang T R, Yang L N, et al. CIRL: controllable imitative reinforcement learning for vision-based self-driving[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 584-599. |
| [10] | Han Y C, Yilmaz A. Learning to drive using sparse imitation reinforcement learning[C]∥The 26th International Conference on Pattern Recognition, Piscataway, USA, 2022: 3736-3742. |
| [11] | Gordon D, Kadian A, Parikh D, et al. SplitNet: Sim2sim and task2task transfer for embodied visual navigation[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Piscataway, USA, 2019: 1022-1031. |
| [12] | Toromanoff M, Wirbel E, Moutarde F. End-to-end model-free reinforcement learning for urban driving using implicit affordances[C] ∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, USA, 2020: 7151-7160. |
| [13] | Mehta A, Subramanian A, Subramanian A. Learning end-to-end autonomous driving using guided auxiliary supervision[C]∥Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, Sofia, Bulgaria, 2020: 1-8. |
| [14] | Agarwal T, Arora H, Schneider J. Learning urban driving policies using deep reinforcement learning[C]∥IEEE International Intelligent Transportation Systems Conference(ITSC), Beijing,China, 2021: 607-614. |
| [15] | Kargar E, Kyrki V. Increasing the efficiency of policy learning for autonomous vehicles by multi-task representation learning[J]. IEEE Transactions on Intelligent Vehicles, 2022, 7(3): 701-710. |
| [16] | 徐国艳, 宗孝鹏, 余贵珍, 等. 基于 DDPG 的无人车智能避障方法研究[J]. 汽车工程, 2019, 41(2): 206-212. |
| Xu Guo-yan, Zong Xiao-peng, Yu Gui-zhen, et al. A research on intelligent obstacle avoidance of unmanned vehicle based on DDPG algorithm[J]. Automotive Engineering, 2019, 41(2): 206-212. | |
| [17] | 王忠立, 王浩, 申艳, 等. 一种多感知多约束奖励机制的驾驶策略学习方法[J]. 吉林大学学报:工学版, 2022, 52(11): 2718-2727. |
| Wang Zhong-li, Wang Hao, Shen Yan, et al. A driving decision⁃making approach based on multi⁃sensing and multi⁃constraints reward function[J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(11): 2718-2727. | |
| [18] | 周治国, 余思雨, 于家宝, 等. 面向无人艇的 T-DQN 智能避障算法研究[J]. 自动化学报, 2023, 49(8): 1645-1655. |
| Zhou Zhi-guo, Yu Si-yu, Yu Jia-bao, et al. Research on T-DPN intelligent obstacle avoidance algorithm of unmanned surface vehicle[J]. Acta Automatica Sinica, 2023, 49(8): 1645-1655. | |
| [19] | Chitta K, Prakash A, Jaeger B, et al. TransFuser: Imitation with transformer-based sensor fusion for autonomous driving[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 12878-12895. |
| [20] | Shao H, Wang L T, Chen R B, et al. Safety-enhanced autonomous driving using interpretable sensor fusion transformer[C]∥Conference on Robot Learning,Auckland, New Zealand, 2023: 726-737. |
| [1] | Zhen-hai GAO,Ming-xi BAO,Rui ZHAO,Ming-hong TANG,Fei GAO. Multimodal trajectory prediction based on target anchor-driven [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 21-30. |
| [2] | Xiang-wen ZHANG,Zi-hao WANG. Electro-hydraulic coordinated control strategy for braking mode switching process of electric vehicles [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 31-43. |
| [3] | Wei LAN,Zheng ZHOU,Guan-yu WANG,Wei WANG,Miao-miao ZHANG. Intelligent fitting method for vehicle design based on machine learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 2858-2863. |
| [4] | Bing ZHU,Peng-xiang MENG,Bin LIU,Jia-yi HAN,Jian ZHAO,Zhi-cheng CHEN,Dong-jian SONG,Xiao-wen TAO. Virtual lane lines fitting method based on traffic environment information [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 2935-2945. |
| [5] | Shou-tao LI,Xiang-yi JIA,Jun ZHU,Hong-yan GUO,Ding-li YU. Uncontrolled intersections decision⁃making method for intelligent driving vehicles based on Level⁃K [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 3069-3078. |
| [6] | Gui-shen YU,Xin CHEN,Yue TANG,Chun-hui ZHAO,Ai-jia NIU,Hui CHAI,Jing-xin NA. Effect of laser surface treatment on the shear strength of aluminum-aluminum bonding joints [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2555-2569. |
| [7] | Jun-wu ZHAO,Ting QU,Yun-feng HU. Trajectory planning for intelligent vehicles based on adaptive sampling [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2802-2816. |
| [8] | Jin-wu GAO,Shao-long SUN,Shun-yao WANG,Bing-zhao GAO. Speed fluctuation suppression strategy of range extender based on motor torque compensation [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2475-2486. |
| [9] | Mei-xia JIA,Jian-jun HU,Feng XIAO. Multi⁃physics simulation method of vehicle motor under varying working conditions based on multi⁃software combination [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1862-1872. |
| [10] | Xue-wei SONG,Ze-ping YU,Yang XIAO,De-ping WANG,Quan YUAN,Xin-zhuo LI,Jia-wen ZHENG. Research progress on the performance changes of lithium⁃ion batteries after aging [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1817-1833. |
| [11] | Chun XIAO,Zi-chun YI,Bing-yin ZHOU,Shao-rui ZHANG. Fuzzy energy management strategy of fuel cell electric vehicle based on improved pigeon⁃inspired optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1873-1882. |
| [12] | Jian WANG,Chen-wei JIA. Trajectory prediction model for intelligent connected vehicle [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1963-1972. |
| [13] | Wei-dong LI,Cao-yuan MA,Hao SHI,Heng CAO. An automatic driving decision control algorithm based on hierarchical reinforcement learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1798-1805. |
| [14] | Dang LU,Yan-ru SUO,Yu-hang SUN,Hai-dong WU. Estimation of tire camber and sideslip combined mechanical characteristics based on dimensionless expression [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1516-1524. |
| [15] | Zi-hao SHEN,Yong-sheng GAO,Hui WANG,Pei-qian LIU,Kun LIU. Deep deterministic policy gradient caching method for privacy protection in Internet of Vehicles [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1638-1647. |
|
||