吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (3): 986-992.doi: 10.13229/j.cnki.jdxbgxb.20240216
基于密集卷积生成对抗网络与关键帧的说话人脸视频生成优化算法
季渊1,2( ),虞雅淇1
),虞雅淇1
- 1.上海大学 微电子研究与开发中心,上海 200444
2.上海大学 机电工程与自动化学院,上海 200444
Optimization algorithm for speech facial video generation based on dense convolutional generative adversarial networks and keyframes
Yuan JI1,2(),Ya-qi YU1
- 1.Microelectronics Research and Development Center,Shanghai University,Shanghai 200444,China
2.School of Mechatronic Engineering and Automation,Shanghai University,Shanghai 200444,China
摘要:
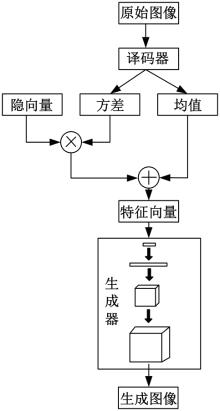
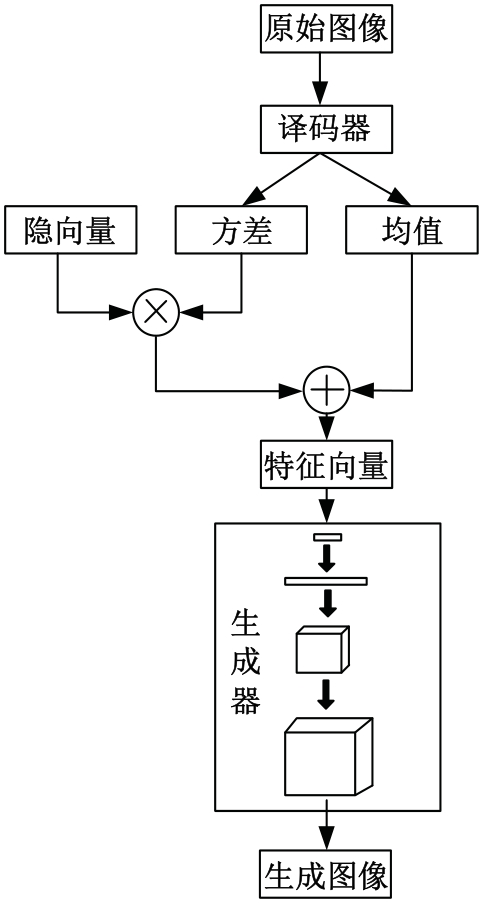
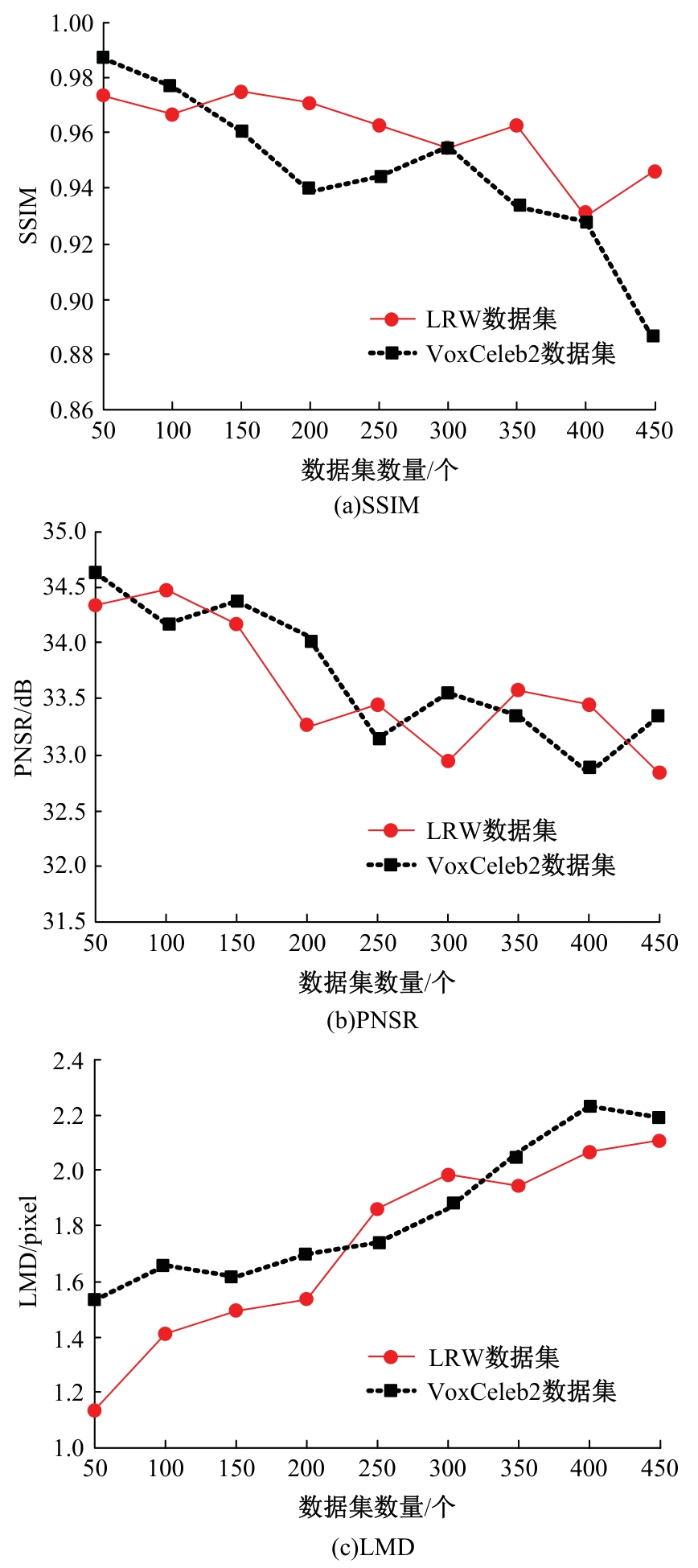
为了提高说话人脸生成视频的真实感和自然度,更准确地反映说话人的语音内容和面部表情,提出了基于密集卷积生成对抗网络与关键帧的说话人脸视频生成优化算法。采用边界框回归法修正人脸的候选窗,基于关键帧比对人脸特征,获取说话人脸信息。通过验证集搜索出最优的超参量集合,建立标准正态分布的随机特征矢量,计算判别器内部参量,生成说话人脸视频。使用判别网络的目标函数,修正先验信息,选取符合真实的修复结果,实现说话人脸视频生成优化。实验证明:本文算法的检测召回率高于96%,SSIM、PNSR和LMD指标分别为0.99、34.7 dB和2.2 pixel,视频真实性为74.1%,具有较好的视频生成效果。
中图分类号:
- TP391


| 1 | 李海烽, 张雪英, 段淑斐, 等. 融合生成对抗网络与时间卷积网络的普通话情感识别[J]. 浙江大学学报:工学版,2023,57(9): 1865-1875. |
| Li Hai-feng, Zhang Xue-ying, Duan Shu-fei, et al. Fusing generative adversarial network and temporal convolutional network for Mandarin emotion recognition[J]. Journal of Zhejiang University(Engineering Science), 2023,57 (9): 1865-1875. | |
| 2 | 孙锐, 孙琦景, 单晓全, 等.基于多残差动态融合生成对抗网络的人脸素描-照片合成方法[J]. 模式识别与人工智能, 2022,35(3): 207-222. |
| Sun Rui, Sun Qi-jing, Shan Xiao-quan, et al. Face sketch-photo synthesis method based on multi-residual dynamic fusion generative adversarial networks[J]. Pattern Recognition and Artificial Intelligence, 2022, 35 (3): 207-2022. | |
| 3 | Fan X Q, Raza S A, Yan H. Edge-aware motion based facial micro-expression generation with attention mechanism[J].Pattern Recognition Letters,2022,162:97-104. |
| 4 | 刘安阳, 赵怀慈, 蔡文龙, 等. 基于主动判别机制的自适应生成对抗网络图像去模糊算法[J]. 计算机应用, 2023, 43(7): 2288-2294. |
| Liu An-yang, Zhao Huai-ci, Cai Wen-long, et al. Adaptive image deblurring generative adversarial network algorithm based on active discrimination mechanism[J]. Journal of Computer Applications, 2023,43 (7): 2288-2294. | |
| 5 | 陈北京, 李天牧, 王金伟, 等. 基于四元数的强泛化性GAN生成人脸检测算法[J]. 计算机辅助设计与图形学学报, 2022, 34(5): 734-742. |
| Chen Bei-jing, Li Tian-mu, Wang Jin-wei, et al. GAN-generated face detection with strong generalization ability based on quaternions[J]. Journal of Computer-Aided Design & Computer Graphics, 2022, 34 (5): 734-742. | |
| 6 | 王鹏, 喻乐延, 舒华忠, 等. 注意力融合双流特征的局部GAN生成人脸检测算法[J]. 东南大学学报: 自然科学版, 2023, 53(3): 543-551. |
| Wang Peng, Yu Le-yan, Shu Hua-zhong, et al. Locally GAN-generated face detection algorithm based on dual-stream features fused by attention[J]. Journal of Southeast University(Natural Science Edition), 2023,53 (3): 543-551. | |
| 7 | Zeng D, Zhao S T, Zhang J J, et al. Expression-tailored talking face generation with adaptive cross-modal weighting[J].Neurocomputing, 2022, 511(28): 117-130. |
| 8 | Andrea V, Carlos B. Multimodal attention for lip synthesis using conditional generative adversarial networks[J].Speech Communication: An International Journal,2023,153:No. 102959. |
| 9 | 温佩芝, 陈君谋, 肖雁南, 等.基于生成式对抗网络和多级小波包卷积网络的水下图像增强算法[J]. 浙江大学学报: 工学版, 2022, 56(2): 213-224. |
| Wen Pei-zhi, Chen Jun-mou, Xiao Yan-nan, et al. Underwater image enhancement algorithm based on GAN and multi-level wavelet CNN[J]. Journal of Zhejiang University (Engineering Science), 2022, 56 (2): 213-224. | |
| 10 | Fang Z, Liu Z, Liu T T, et al. Facial expression GAN for voice-driven face generation[J].The Visual Computer,2022,38(3):1151-1164. |
| 11 | Tang H, Shao L, Torr P H, et al. Bipartite graph reasoning GANs for person pose and facial image synthesis[J].International Journal of Computer Vision,2023,131(3): 644-658. |
| 12 | 侯向丹, 刘昊然, 刘洪普. 基于卷积自编码生成式对抗网络的高分辨率破损图像修复[J]. 中国图象图形学报, 2022, 27(5): 1645-1656. |
| Hou Xiang-dan, Liu Hao-ran, Liu Hong-pu. High-resolution damaged images restoration based on convolutional auto-encoder generative adversarial network[J]. Journal of Image and Graphics, 2022, 27 (5): 1645-1656. | |
| 13 | Li B, Zhang W, Li X B, et al. ECG signal reconstruction based on facial videos via combined explicit and implicit supervision[J].Knowledge-based Systems, 2023, 272(19): No.110608. |
| 14 | 张昊, 段锦, 刘举, 等. 基于密集梯度生成对抗网络的偏振图像融合算法[J]. 光学技术, 2023, 49(3): 354-360. |
| Zhang Hao, Duan Jin, Liu Ju, et al. Polarization image fusion algorithm based on dense gradient generative adversarial networks[J]. Optical Technique, 2023,49 (3): 354-360. | |
| 15 | Wu S K, Liu W M, Wang Q Q, et al. RefFaceNet: reference-based face image generation from line art drawings[J].Neurocomputing,2022,488(1):154-167. |
| 16 | Han Y M, Zhuo T, Zhang P, et al. One-shot video graph generation for explainable action reasoning[J]. Neurocomputing, 2022, 488(1): 212-225. |
| 17 | 王宏飞, 程鑫, 赵祥模, 等.光流与纹理特征融合的人脸活体检测算法[J]. 计算机工程与应用, 2022, 58(6): 170-176. |
| Wang Hong-fei, Cheng Xin, Zhao Xiang-mo, et al. Face liveness detection based on fusional optical flow and texture features[J]. Computer Engineering and Applications, 2022, 58 (6): 170-176. | |
| 18 | Xing L, Lin H R, Zhang D, et al. Facial characteristics of air gun array wavelets in the time and frequency domain under real conditions[J].Journal of Applied Geophysics,2022,199: No.104591. |
| 19 | 刘斌, 王耀威. 基于生成对抗网络的图像超分辨率重建算法[J]. 计算机仿真, 2023, 40(10): 269-273. |
| Liu Bin, Wang Yao-wei. Super resolution image reconstruction algorithm based on generated countermeasure network[J].Computer Simulation,2023,40(10): 269-273. |
| [1] | 李学军,权林霏,刘冬梅,于树友. 基于Faster-RCNN改进的交通标志检测算法[J]. 吉林大学学报(工学版), 2025, 55(3): 938-946. |
| [2] | 徐涛,孔帅迪,刘才华,李时. 异构机密计算综述[J]. 吉林大学学报(工学版), 2025, 55(3): 755-770. |
| [3] | 才华,朱瑞昆,付强,王伟刚,马智勇,孙俊喜. 基于隐式关键点互联的人体姿态估计矫正器算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1061-1071. |
| [4] | 刘广文,谢欣月,付强,才华,王伟刚,马智勇. 基于时空模板焦点注意的Transformer目标跟踪算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1037-1049. |
| [5] | 李扬,李现国,苗长云,徐晟. 基于双分支通道先验和Retinex的低照度图像增强算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1028-1036. |
| [6] | 程德强,刘规,寇旗旗,张剑英,江鹤. 基于自适应大核注意力的轻量级图像超分辨率网络[J]. 吉林大学学报(工学版), 2025, 55(3): 1015-1027. |
| [7] | 曹毅,夏宇,高清源,叶培涛,叶凡. 基于超连接图卷积网络的骨架行为识别方法[J]. 吉林大学学报(工学版), 2025, 55(2): 731-740. |
| [8] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [9] | 才华,郑延阳,付强,王晟宇,王伟刚,马智勇. 基于多尺度候选融合与优化的三维目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(2): 709-721. |
| [10] | 蔡晓东,周青松,张言言,雪韵. 基于动静态和关系特征全局捕获的社交推荐模型[J]. 吉林大学学报(工学版), 2025, 55(2): 700-708. |
| [11] | 郑利民,陈双,李刚. YOLOv5网络算法下交通监控视频违章车辆多目标检测[J]. 吉林大学学报(工学版), 2025, 55(2): 693-699. |
| [12] | 车翔玖,武宇宁,刘全乐. 基于因果特征学习的有权同构图分类算法[J]. 吉林大学学报(工学版), 2025, 55(2): 681-686. |
| [13] | 郭晓然,王铁君,闫悦. 基于局部注意力和本地远程监督的实体关系抽取方法[J]. 吉林大学学报(工学版), 2025, 55(1): 307-315. |
| [14] | 汪豪,赵彬,刘国华. 基于时间和运动增强的视频动作识别[J]. 吉林大学学报(工学版), 2025, 55(1): 339-346. |
| [15] | 张曦,库少平. 基于生成对抗网络的人脸超分辨率重建方法[J]. 吉林大学学报(工学版), 2025, 55(1): 333-338. |
|
||