吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (3): 1037-1049.doi: 10.13229/j.cnki.jdxbgxb20230544
基于时空模板焦点注意的Transformer目标跟踪算法
刘广文1( ),谢欣月1,付强2,才华1(),王伟刚3,马智勇3
),谢欣月1,付强2,才华1(),王伟刚3,马智勇3
- 1.长春理工大学 电子信息工程学院,长春 130022
2.长春理工大学 空间光电技术研究所,长春 130022
3.吉林大学第一医院 泌尿外二科,长春 130061
Spatiotemporal Transformer with template attention for target tracking
Guang-wen LIU1(),Xin-yue XIE1,Qiang FU2,Hua CAI1(),Wei-gang WANG3,Zhi-yong MA3
- 1.School of Electronic Information Engineering,Changchun University of Science and Technology,Changchun 130022,China
2.School of Opto-Electronic Engineer,Changchun University of Science and Technology,Changchun 130022,China
3.No. 2 Department of Urology,the First Hospital of Jilin University,Changchun 130061,China
摘要:
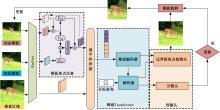
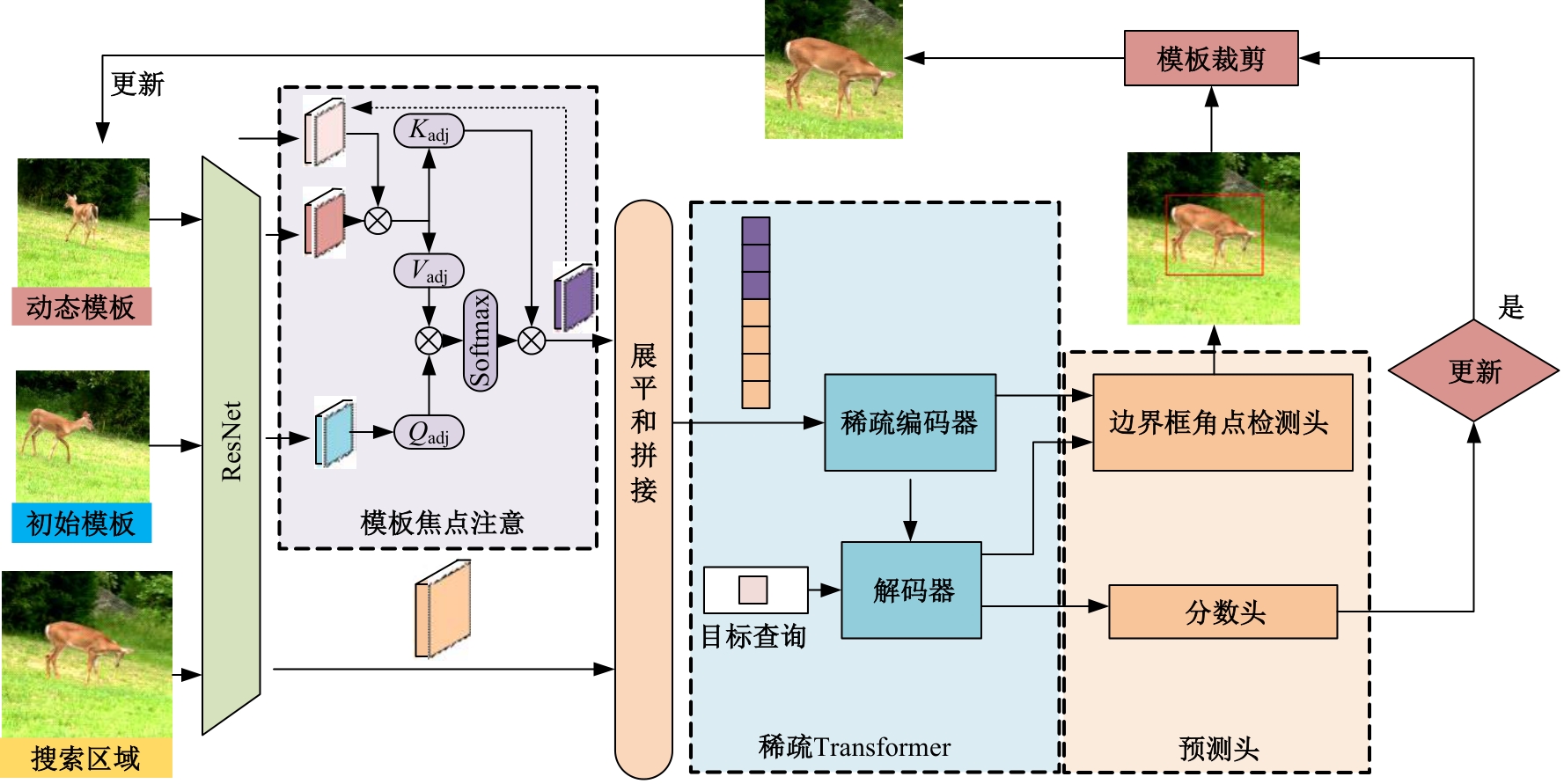
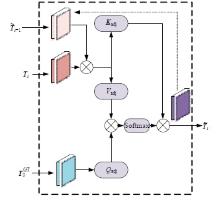
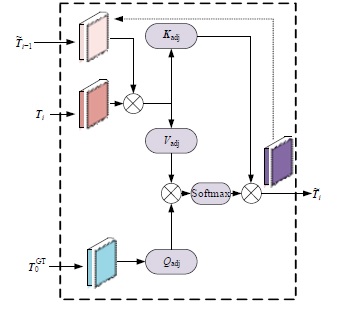
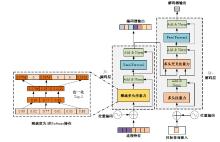
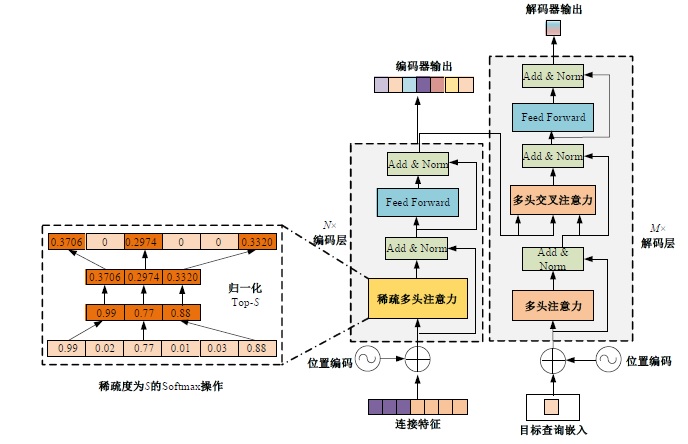
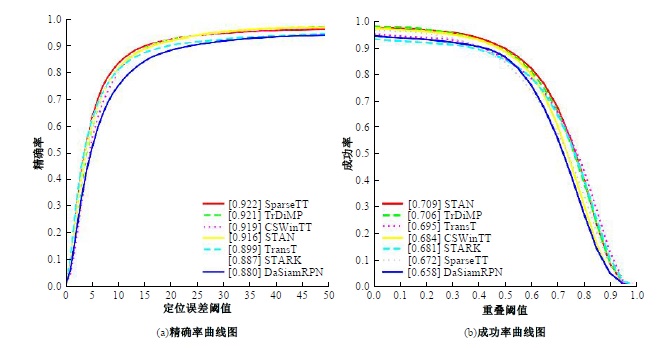
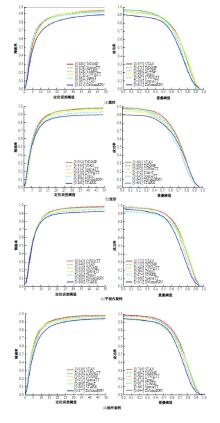
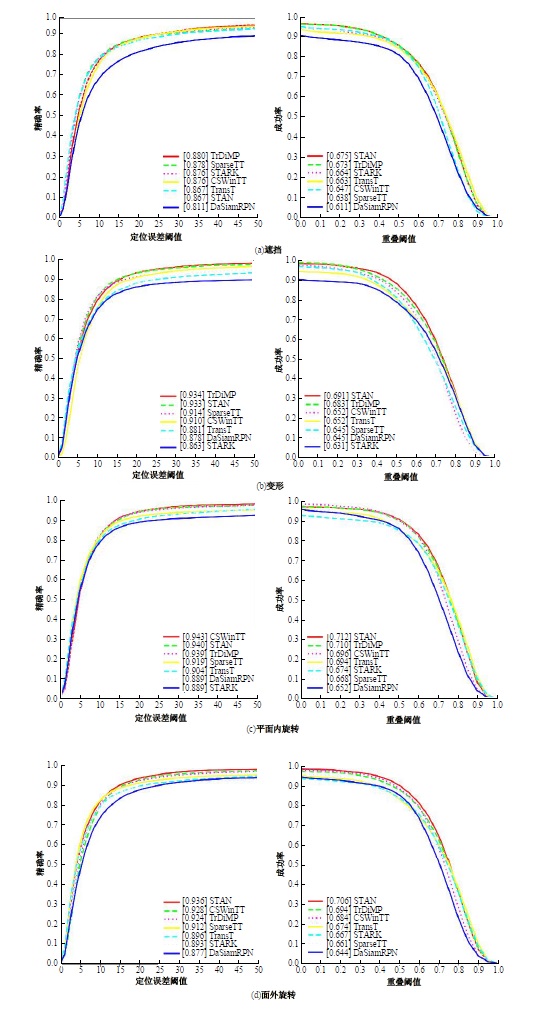
针对现有的视觉目标跟踪方法只使用第一帧的目标区域作为模板,导致在快速变化和复杂背景中很容易失效的问题,本文提出了一种基于Transformer的目标跟踪算法,它关注模板中的目标焦点信息,并动态更新模板特征。为了减小背景信息对注意力的干扰,本算法使用稀疏Transformer模块实现特征信息的交互;还提出了模板焦点注意模块,用于对动态模板特征和初始模板特征进行目标焦点的关注,以保留初始模板中高度可靠的特征信息。实验结果表明:本文算法在OTB100基准测试中成功率和准确率分别达到70.9%和91.6%,相较于同类模板更新算法STARK成功率和精确率分别提升4.11%和3.27%。该算法有效解决了现有视觉对象跟踪方法的局限性问题,提高了跟踪的准确性和鲁棒性。
中图分类号:
- TP391



| 1,1 | Marvasti-Zadeh S M, Cheng L, Ghanei-Yakhdan H, et al. Deep learning for visual tracking: a comprehensive survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(5): 3943-3968. |
| 2 | Huang K, Hao Q. Joint multi-object detection and tracking with camera-LiDAR fusion for autonomous driving[C]∥IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Pruge, Czech, 2021: 6983-6989. |
| 3 | Ye J, Fu C, Lin F, et al. Multi-regularized correlation filter for UAV tracking and self-localization[J]. IEEE Transactions on Industrial Electronics, 2021, 69(6): 6004-6014. |
| 4 | Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking[C]∥Computer Vision-ECCV 2016 Workshops, Amsterdam, Holland, 2016: 850-865. |
| 5 | Li B, Yan J, Wu W, et al. High performance visual tracking with siamese region proposal network[C]∥Proceedings of the IEEE Conference on Computer vision and Pattern Recognition,Salt Lake City, USA, 2018: 8971-8980. |
| 6 | Li B, Wu W, Wang Q, et al. Evolution of siamese visual tracking with very deep networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA,2019: 16-20. |
| 7 | Danelljan M, Bhat G, Shahbaz Khan F, et al. Eco: efficient convolution operators for tracking[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Montreal, Canada,2017: 6638-6646. |
| 8 | Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]∥Computer Vision-ECCV 2020. Berlin: Springer, 2020: 213-229. |
| 9 | 张尧, 才华, 李心达, 等. 基于 Adaboost 首帧检测的时空上下文人脸跟踪算法[J]. 吉林大学学报: 理学版, 2020, 58(2): 314-320. |
| Zhang Yao, Cai Hua, Li Xin-da, et al. Spatio-temporal context face tracking algorithm based on adaboost first frame detection [J]. Journal of Jilin University (Science Edition), 2020,58 (2): 314-320. | |
| 10 | Yan B, Peng H, Fu J, et al. Learning spatio-temporal transformer for visual tracking[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision,Montreal, Canada,2021: 10448-10457. |
| 11 | Li B, Yan J, Wu W, et al. High performance visual tracking with siamese region proposal network[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA,2018: 8971-8980. |
| 12 | Li B, Wu W, Wang Q, et al. Evolution of siamese visual tracking with very deep networks[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA,2019: 15-20. |
| 13 | Zhu Z, Wang Q, Li B, et al. Distractor-aware siamese networks for visual object tracking[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 103-119. |
| 14 | Zhang L, Gonzalez-Garcia A, Weijer J, et al. Learning the model update for siamese trackers[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision,Seoul,South Korea, 2019: 4010-4019. |
| 15 | 才华, 王学伟, 付强, 等. 基于动态模板更新的孪生网络目标跟踪算法[J]. 吉林大学学报: 工学版, 2022, 52(5): 1106-1116. |
| Cai Hua, Wang Xue-wei, Fu Qiang, et al.Siamese network target tracking algorithm based on dynamic template updating[J]. Journal of Jilin University (Engineering Edition), 2022, 52(5): 1106-1116. | |
| 16 | Zhao M, Okada K, Inaba M. Trtr: visual tracking with transformer[J/OL]. [2023-05-17]. |
| 17 | Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]∥Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, 2020: 213-229. |
| 18 | Wang N, Zhou W, Wang J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1571-1580. |
| 19 | Chen X, Yan B, Zhu J, et al. Transformer tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville,USA, 2021: 8126-8135. |
| 20 | Fu Z, Fu Z, Liu Q, et al. SparseTT: visual tracking with sparse transformers[J/OL]. [2023-05-17]. |
| 21 | Song Z, Yu J, Chen Y P P, et al. Transformer tracking with cyclic shifting window attention[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 8791-8800. |
| 22 | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J/OL]. [2023-05-17]. |
| 23 | Zhang Z L, Sabuncu M R. Generalized cross entropy loss for training deep neural networks with noisy labels[J/OL]. [2023-05-17]. |
| 24 | Fan H, Lin L, Yang F, et al. Lasot: a high-quality benchmark for large-scale single object tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5374-5383. |
| 25 | Huang L, Zhao X, Huang K. Got-10k: a large high-diversity benchmark for generic object tracking in the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(5): 1562-1577. |
| 26 | Lin T Y, Maire M, Belongie S, et al. Microsoft coco: common objects in context[J/OL] .[2023-05-17]. |
| 27 | Wu Y, Lim J, Yang M H. Object tracking benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834-1848. |
| 28 | Muller M, Bibi A, Giancola S, et al. Trackingnet: a large-scale dataset and benchmark for object tracking in the wild[J/OL] [2023-05-17]. |
| [1] | 程德强,刘规,寇旗旗,张剑英,江鹤. 基于自适应大核注意力的轻量级图像超分辨率网络[J]. 吉林大学学报(工学版), 2025, 55(3): 1015-1027. |
| [2] | 才华,郑延阳,付强,王晟宇,王伟刚,马智勇. 基于多尺度候选融合与优化的三维目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(2): 709-721. |
| [3] | 才华,寇婷婷,杨依宁,马智勇,王伟刚,孙俊喜. 基于轨迹优化的三维车辆多目标跟踪[J]. 吉林大学学报(工学版), 2024, 54(8): 2338-2347. |
| [4] | 朱圣杰,王宣,徐芳,彭佳琦,王远超. 机载广域遥感图像的尺度归一化目标检测方法[J]. 吉林大学学报(工学版), 2024, 54(8): 2329-2337. |
| [5] | 蒋磊,王子其,崔振宇,常志勇,时小虎. 基于循环结构的视觉Transformer[J]. 吉林大学学报(工学版), 2024, 54(7): 2049-2056. |
| [6] | 孙铭会,薛浩,金玉波,曲卫东,秦贵和. 联合时空注意力的视频显著性预测[J]. 吉林大学学报(工学版), 2024, 54(6): 1767-1776. |
| [7] | 王殿伟,张池,房杰,许志杰. 基于高分辨率孪生网络的无人机目标跟踪算法[J]. 吉林大学学报(工学版), 2024, 54(5): 1426-1434. |
| [8] | 王宇,赵凯. 基于亚像素定位的人体姿态热图后处理[J]. 吉林大学学报(工学版), 2024, 54(5): 1385-1392. |
| [9] | 高云龙,任明,吴川,高文. 基于注意力机制改进的无锚框舰船检测模型[J]. 吉林大学学报(工学版), 2024, 54(5): 1407-1416. |
| [10] | 毛琳,苏宏阳,杨大伟. 时间显著注意力孪生跟踪网络[J]. 吉林大学学报(工学版), 2024, 54(11): 3327-3337. |
| [11] | 孙文财,胡旭歌,杨志发,孟繁雨,孙微. 融合GPNet与图像多尺度特性的红外-可见光道路目标检测优化方法[J]. 吉林大学学报(工学版), 2024, 54(10): 2799-2806. |
| [12] | 刘晶红,邓安平,陈琪琪,彭佳琦,左羽佳. 基于多重注意力机制的无锚框目标跟踪算法[J]. 吉林大学学报(工学版), 2023, 53(12): 3518-3528. |
| [13] | 王侃,苏航,曾浩,覃剑. 表观增强的深度目标跟踪算法[J]. 吉林大学学报(工学版), 2022, 52(11): 2676-2684. |
| [14] | 曹洁,屈雪,李晓旭. 基于滑动特征向量的小样本图像分类方法[J]. 吉林大学学报(工学版), 2021, 51(5): 1785-1791. |
| [15] | 徐涛,马克,刘才华. 基于深度学习的行人多目标跟踪方法[J]. 吉林大学学报(工学版), 2021, 51(1): 27-38. |
|
||