吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (12): 4052-4062.doi: 10.13229/j.cnki.jdxbgxb.20240555
• 计算机科学与技术 • 上一篇
基于Diff-AdvGAN的图像对抗样本生成方法
赵宏( ),马宇轩,宋馥荣
),马宇轩,宋馥荣
- 兰州理工大学 计算机与通信学院,兰州 730050
Image adversarial examples generation based on Diff⁃AdvGAN
Hong ZHAO(),Yu-xuan MA,Fu-rong SONG
- School of Computer and Communication,Lanzhou University of Technology,Lanzhou 730050,China
摘要:
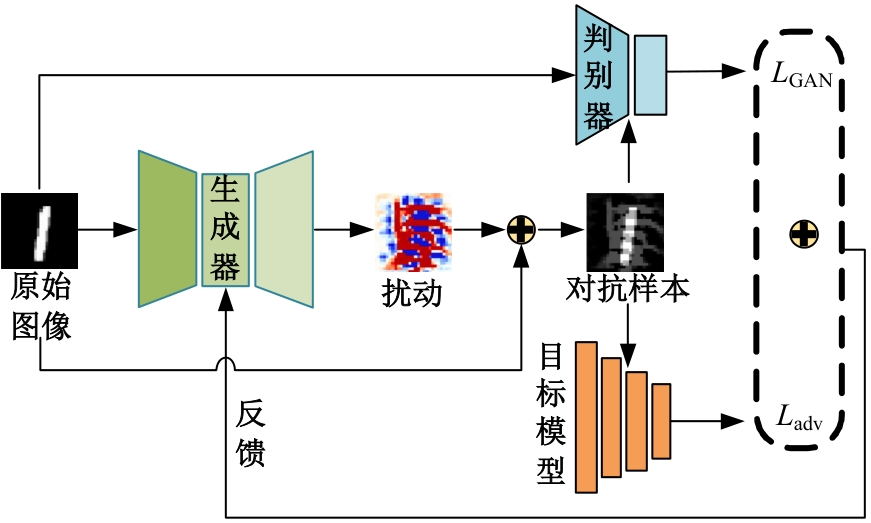
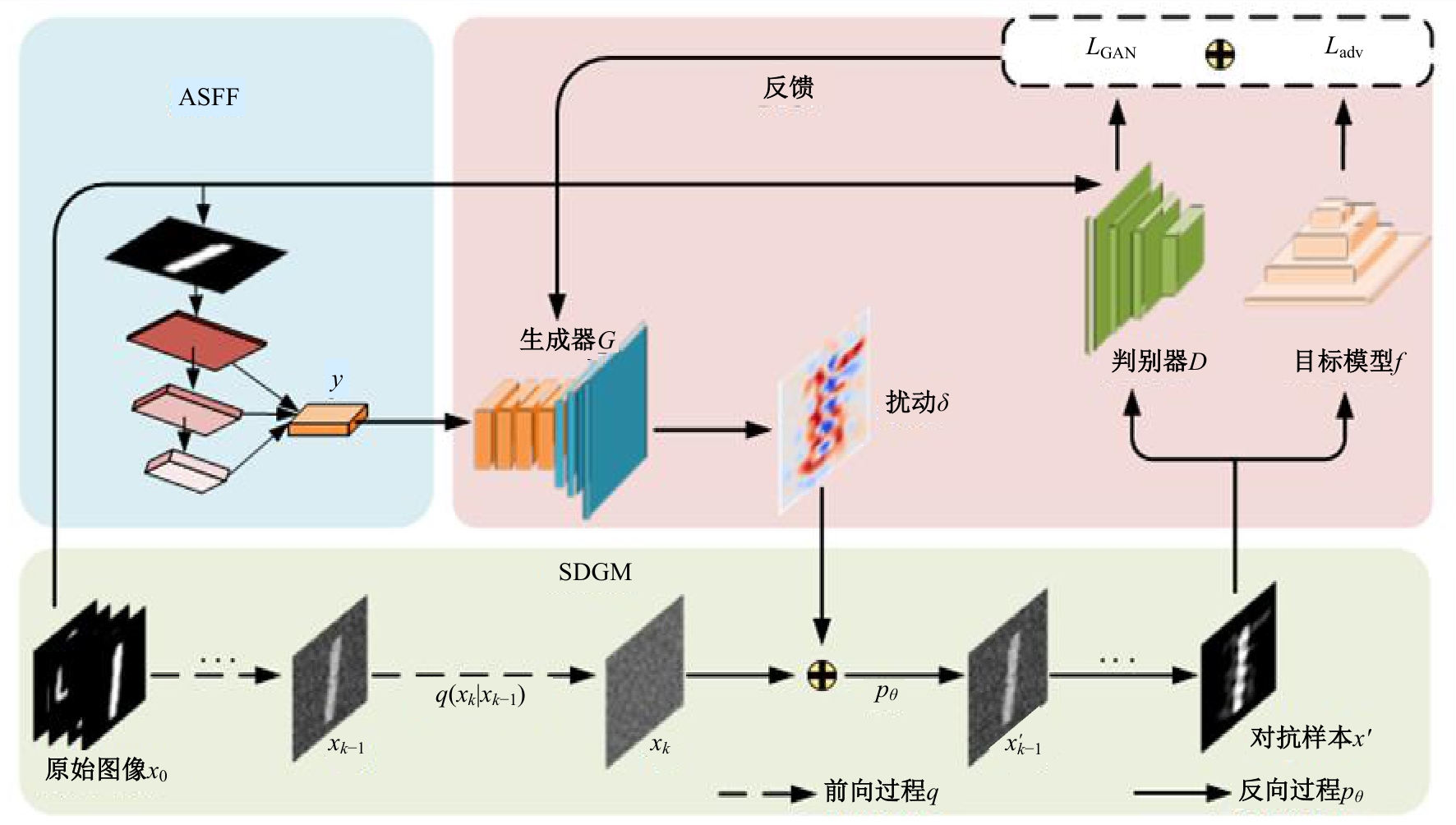
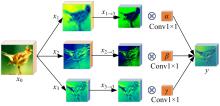
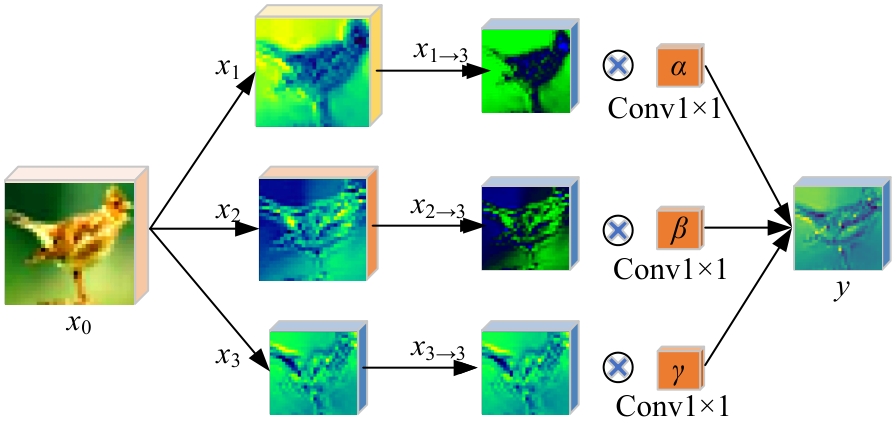
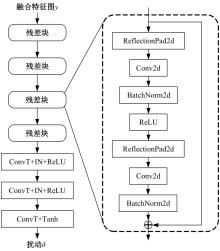
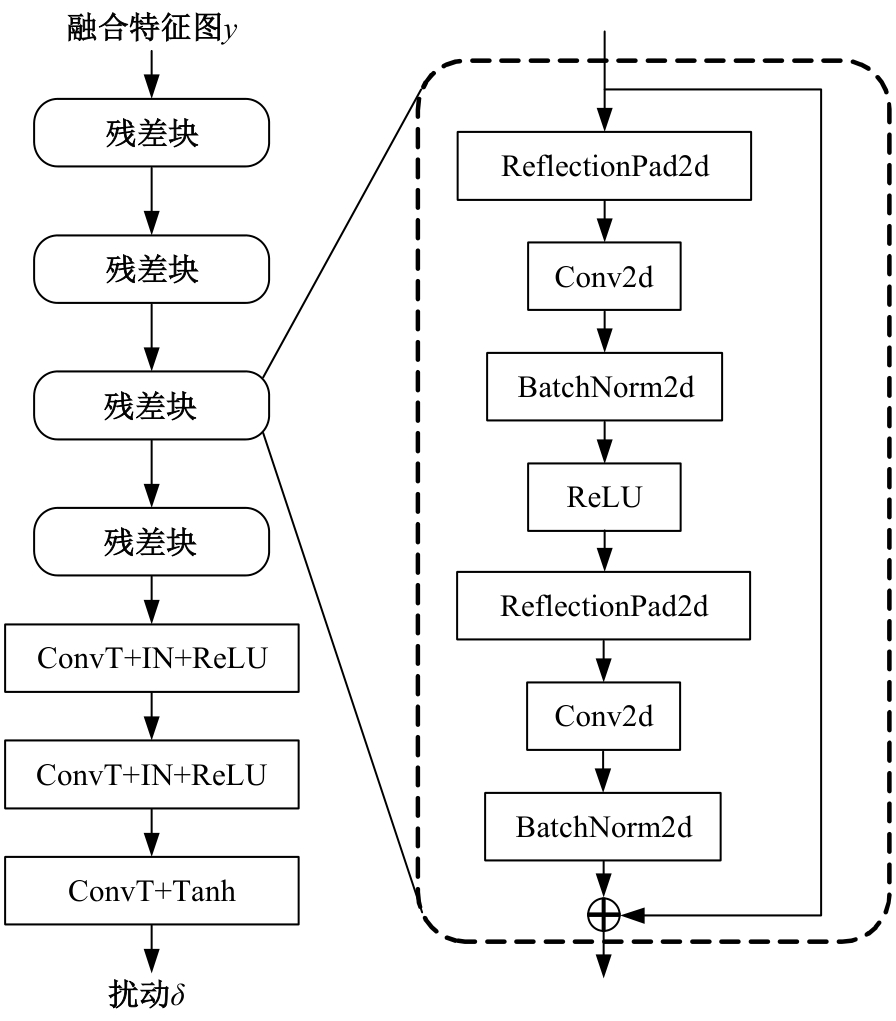
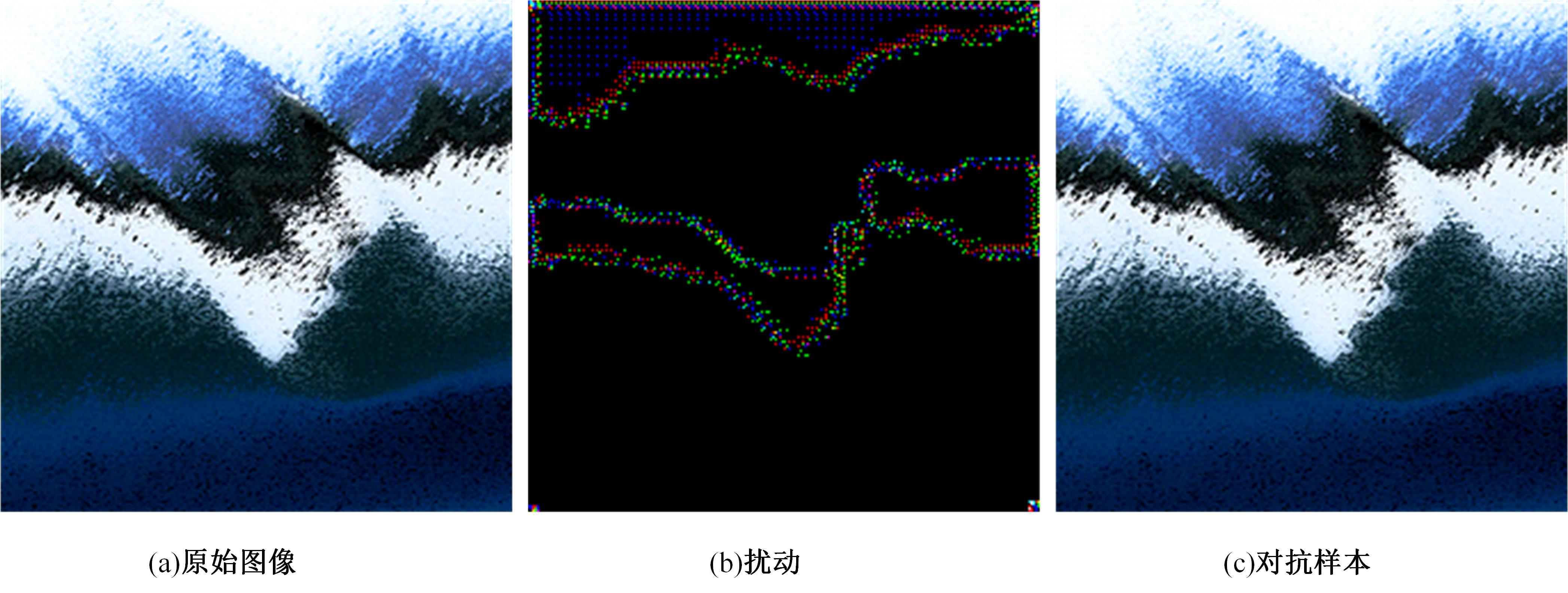
针对基于生成对抗网络的对抗样本生成方法(AdvGAN)所存在的扰动偏离关键区域且可控性不强,导致对抗样本攻击效果欠佳、真实性较低的问题,提出了Diff-AdvGAN对抗样本生成方法。首先,利用自适应空间特征融合模块(ASFF)融合图像的不同尺度特征图。其次,将融合后的特征图输入生成器生成扰动,并使用随机微分引导模块(SDGM)增强扰动的可控性,生成对抗样本。最后,将对抗样本输入判别器和目标模型,迭代计算损失值并反馈至生成器,以生成攻击性能较强的扰动。实验结果表明,Diff-AdvGAN方法在MNIST数据集上对LeNet C、VGG11和C&Wmodel模型的攻击成功率均大于99%,在CIFAR-10数据集上对ResNet18和ResNet32模型的攻击成功率分别为96.17%和95.82%;同时生成的扰动处于图像关键区域,稀疏性高、幅度小,均优于对比方法。
中图分类号:
- TP391
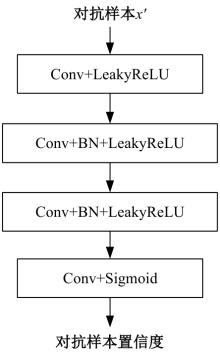
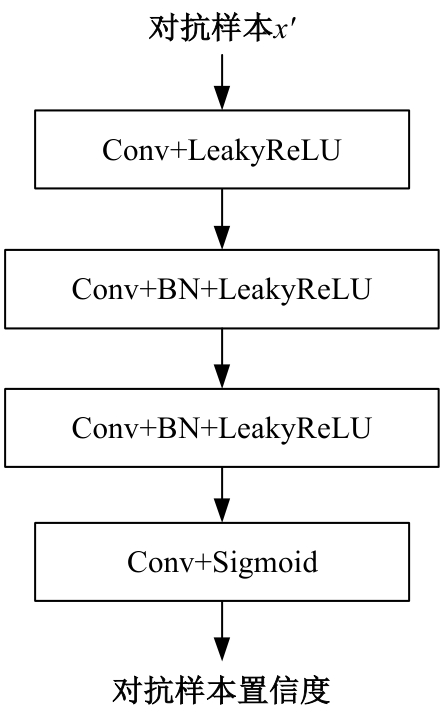
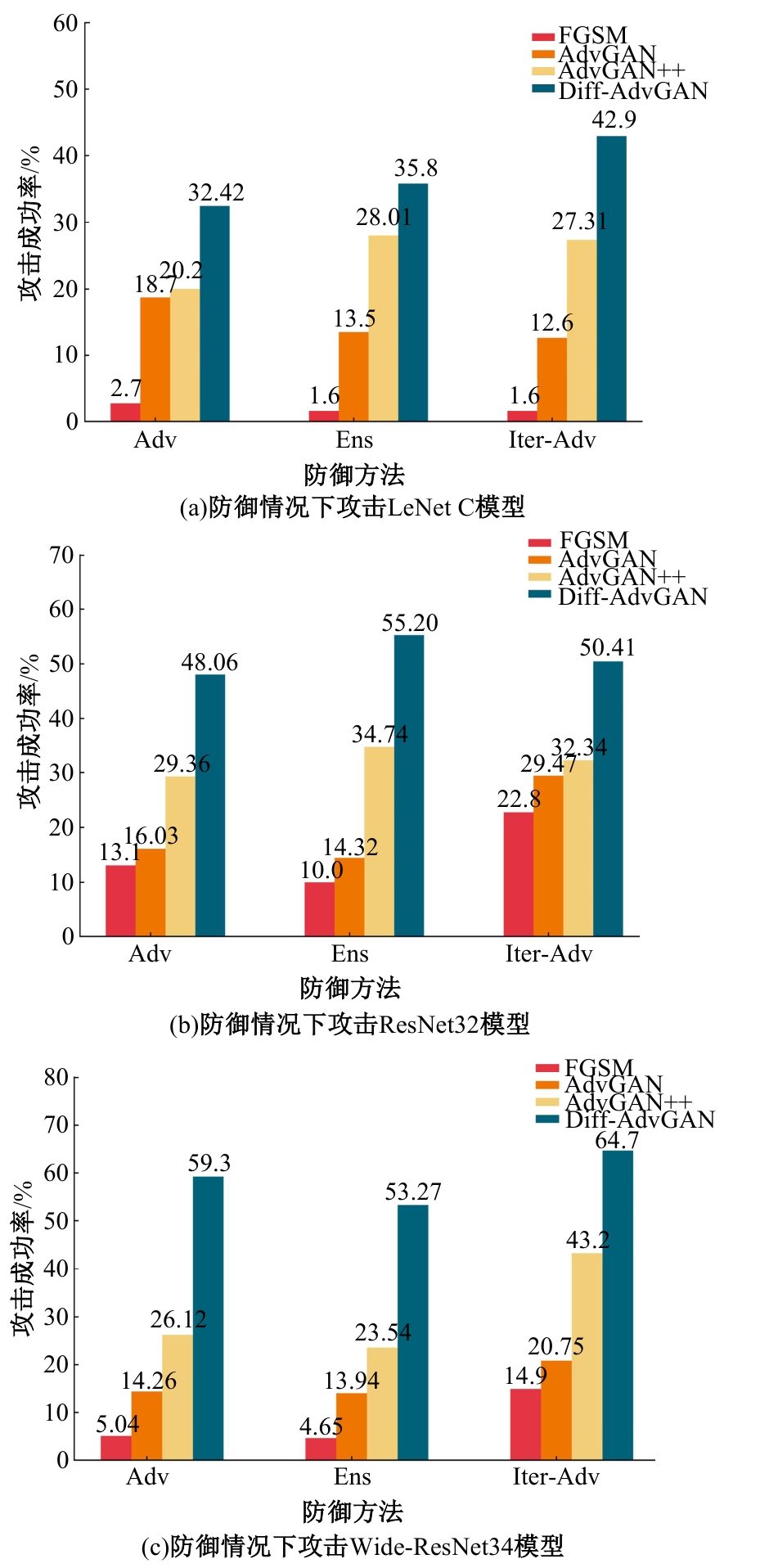





| [1] | Kim I, Baek W, Kim S. Spatially attentive output layer for image classification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Alamitos, CA, USA, 2020: 9533-9542. |
| [2] | Boutros F, Damer N, Kirchbuchner F, et al. Elasticface: Elastic margin loss for deep face recognition[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 2022: 1578-1587. |
| [3] | Hausler S, Garg S, Xu M, et al. Patch-netvlad: Multi-scale fusion of locally-global descriptors for place recognition[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Alamitos, CA, USA, 2021: 14141-14152. |
| [4] | Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[C]∥2nd International Conference on Learning Representations, Banff, AB, Canada, 2014: 23-41. |
| [5] | 吉顺慧, 胡黎明, 张鹏程, 等. 基于稀疏扰动的对抗样本生成方法[J]. 软件学报, 2023, 34(9): 4003-4017. |
| Ji Shun-hui, Hu Li-ming, Zhang Peng-cheng, et al. Adversarial example generation method based on sparse perturbation[J]. Journal of Software, 2023, 34(9): 4003-4017. | |
| [6] | Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J/OL]. [2025-05-01]. |
| [7] | Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world[C]∥5th International Conference on Learning Representations, Toulon, France, 2017: 1-14. |
| [8] | Carlini N, Wagner D. Towards evaluating the robustness of neural networks[C]∥2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 2017: 39-57. |
| [9] | Baluja S, Fischer I. Adversarial transformation networks: learning to generate adversarial examples[J/OL]. [2025-05-01]. |
| [10] | Zhao Z L, Dua D, Singh S. Generating natural adversarial examples[C]∥6th International Conference on Learning Representations, Vancouver, BC, Canada, 2018: 1-15. |
| [11] | Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks[C]∥Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia:, 2017: 214-223. |
| [12] | Zhang W J. Generating adversarial examples in one shot with image-to-image translation GAN[J]. IEEE Access, 2019, 7: 151103-151119. |
| [13] | Xiao C W, Li B, Zhu J Y, et al. Generating adversarial examples with adversarial networks[C]∥Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 2018: 3905-3911. |
| [14] | 黄帅娜, 李玉祥, 毛岳恒, 等. 基于集成advGAN的黑盒迁移对抗攻击[J]. 吉林大学学报: 工学版, 2022, 52(10): 2391-2398. |
| Huang Shuai-na, Li Yu-xiang, Mao Yue-heng, et al. Black-box transferable adversarial attacks based on ensemble advGAN[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(10): 2391-2398. | |
| [15] | 刘悦文, 孙子文. 抵御对抗攻击的生成对抗网络IWSN入侵检测模型[J]. 江苏大学学报: 自然科学版, 2025, 46(5): 562-569. |
| Liu Yue-wen, Sun Zi-wen. Intrusion detection model based on generative adversarial networks in IWSN against adversarial attacks[J]. Journal of Jiangsu University (Natural Science Edition), 2025, 46(5): 562-569. | |
| [16] | Jandial S, Mangla P, Varshney S, et al. AdvGAN++: harnessing latent layers for adversary generation[C]∥2019 IEEE/CVF International Conference on Computer Vision Workshop, Los Alamitos, CA, USA, 2019: 2045-2048. |
| [17] | Singh J, Gould S, Zheng L. High-fidelity guided image synthesis with latent diffusion models[C]∥2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 2023: 5997-6006. |
| [18] | Podell D, English Z, Lacey K, et al. SDXL: improving latent diffusion models for high-resolution image synthesis[J/OL]. [2024-05-03]. |
| [19] | Dai X L, Liang K S, Xiao B. AdvDiff: generating unrestricted adversarial examples using diffusion models[J/OL]. [2024-05-03]. |
| [20] | Chen X Q, Gao X T, Zhao J J, et al. Advdiffuser: Natural adversarial example synthesis with diffusion models[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 4562-4572. |
| [21] | Liu D C, Wang X J, Peng C L, et al. Adv-diffusion: Imperceptible adversarial face identity attack via latent diffusion model[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(4): 3585-3593. |
| [22] | Liu S T, Huang D, Wang Y H. Learning spatial fusion for single-shot object detection[J/OL]. [2024-05-03]. |
| [23] | Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851. |
| [24] | Song J M, Meng C L, Ermon S. Denoising diffusion implicit models[J/OL]. [2024-05-03]. |
| [25] | Tramèr F, Kurakin A, Papernot N, et al. Ensemble adversarial training: attacks and defenses[C]∥6th International Conference on Learning Representations, Vancouver, BC, Canada, 2018: 1-20. |
| [26] | Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[C]∥6th International Conference on Learning Representations, Vancouver, BC, Canada, 2018: 1-23. |
| [1] | 兰巍,周政,王冠宇,王伟,张苗苗. 基于机器学习的汽车设计智能拟合方法[J]. 吉林大学学报(工学版), 2025, 55(9): 2858-2863. |
| [2] | 朴燕,康继元. RAUGAN:基于循环生成对抗网络的红外图像彩色化方法[J]. 吉林大学学报(工学版), 2025, 55(8): 2722-2731. |
| [3] | 文斌,彭顺,杨超,沈艳军,李辉. 多深度自适应融合去雾生成网络[J]. 吉林大学学报(工学版), 2025, 55(6): 2103-2113. |
| [4] | 刘广文,赵绮莹,王超,高连宇,才华,付强. 基于渐进递归的生成对抗单幅图像去雨算法[J]. 吉林大学学报(工学版), 2025, 55(4): 1363-1373. |
| [5] | 张河山,范梦伟,谭鑫,郑展骥,寇立明,徐进. 基于改进YOLOX的无人机航拍图像密集小目标车辆检测[J]. 吉林大学学报(工学版), 2025, 55(4): 1307-1318. |
| [6] | 季渊,虞雅淇. 基于密集卷积生成对抗网络与关键帧的说话人脸视频生成优化算法[J]. 吉林大学学报(工学版), 2025, 55(3): 986-992. |
| [7] | 张曦,库少平. 基于生成对抗网络的人脸超分辨率重建方法[J]. 吉林大学学报(工学版), 2025, 55(1): 333-338. |
| [8] | 温晓岳,钱国敏,孔桦桦,缪月洁,王殿海. TrafficPro:一种针对城市信控路网的路段速度预测框架[J]. 吉林大学学报(工学版), 2024, 54(8): 2214-2222. |
| [9] | 赖丹晖,罗伟峰,袁旭东,邱子良. 复杂环境下多模态手势关键点特征提取算法[J]. 吉林大学学报(工学版), 2024, 54(8): 2288-2294. |
| [10] | 郭昕刚,何颖晨,程超. 抗噪声的分步式图像超分辨率重构算法[J]. 吉林大学学报(工学版), 2024, 54(7): 2063-2071. |
| [11] | 吕卫,韩镓泽,褚晶辉,井佩光. 基于多模态自注意力网络的视频记忆度预测[J]. 吉林大学学报(工学版), 2023, 53(4): 1211-1219. |
| [12] | 曾春艳,严康,王志锋,王正辉. 多尺度生成对抗网络下图像压缩感知重建算法[J]. 吉林大学学报(工学版), 2023, 53(10): 2923-2931. |
| [13] | 林乐平,卢增通,欧阳宁. 面向非配合场景的人脸重建及识别方法[J]. 吉林大学学报(工学版), 2022, 52(12): 2941-2946. |
| [14] | 黄帅娜,李玉祥,毛岳恒,班爱莹,张志勇. 基于集成advGAN的黑盒迁移对抗攻击[J]. 吉林大学学报(工学版), 2022, 52(10): 2391-2398. |
| [15] | 陈雪云,许韬,黄小巧. 基于条件生成对抗网络的医学细胞图像生成检测方法[J]. 吉林大学学报(工学版), 2021, 51(4): 1414-1419. |
|
||