吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (10): 3384-3393.doi: 10.13229/j.cnki.jdxbgxb.20231415
• 计算机科学与技术 • 上一篇
基于Transformer的双分支检测和重识别的多行人追踪
黄丹丹1( ),张新茹1,刘智1,2,彭刚3
),张新茹1,刘智1,2,彭刚3
- 1.长春理工大学 电子信息工程学院,长春 130022
2.长春理工大学 空间光电技术国家地方联合工程研究中心,长春 130022
3.长春师凯科技产业有限责任公司 研发技术部,长春 130015
Multi-pedestrian tracking based on Transformer double branch detection and re-identification
Dan-dan HUANG1(),Xin-ru ZHANG1,Zhi LIU1,2,Gang PENG3
- 1.School of Electronics and Information Engineering,Changchun University of Science and Technology,Changchun 130022,China
2.National and Local Joint Engineering Research Center of Space Photoelectric Technology,Changchun University of Science and Technology,Changchun 130022,China
3.Changchun Shikai Technology Industry Co. ,Research and Development Center,Changchun 130015,China
摘要:
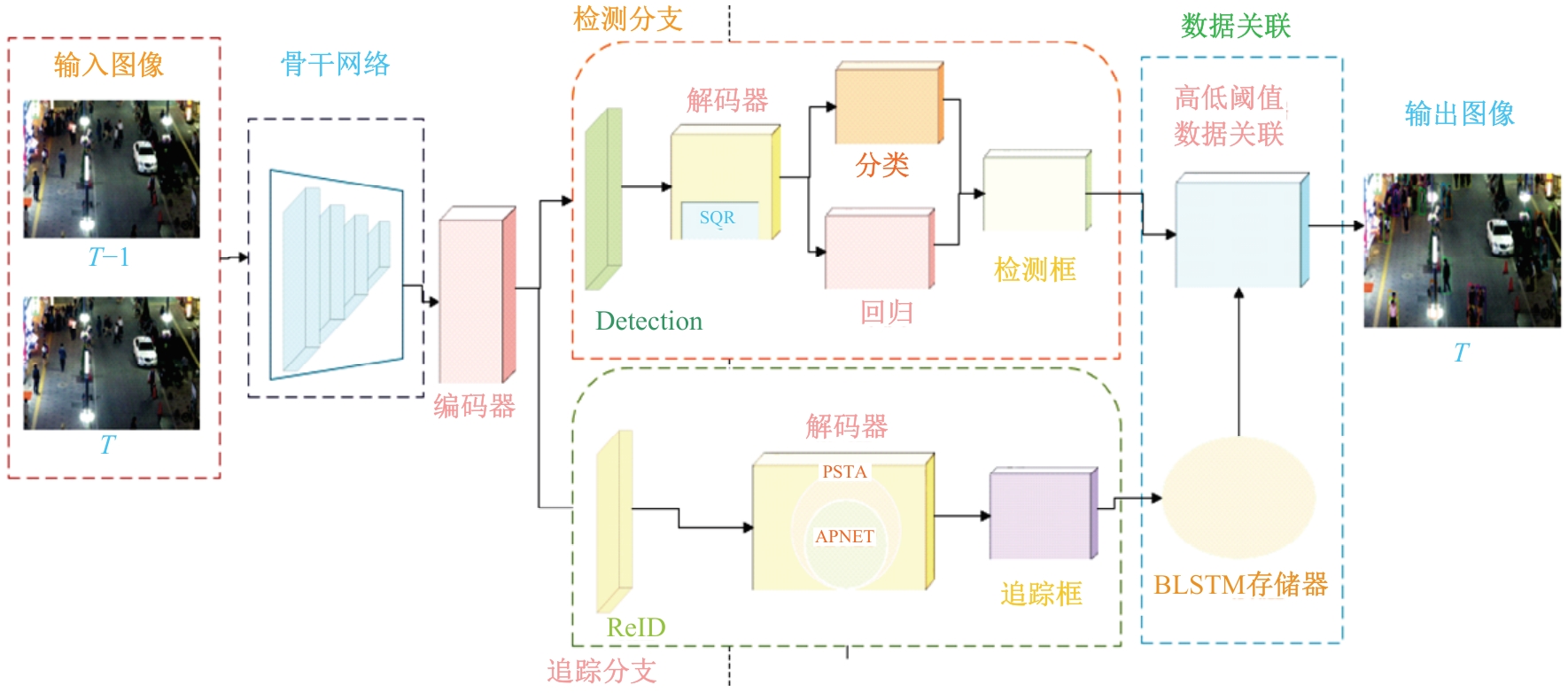
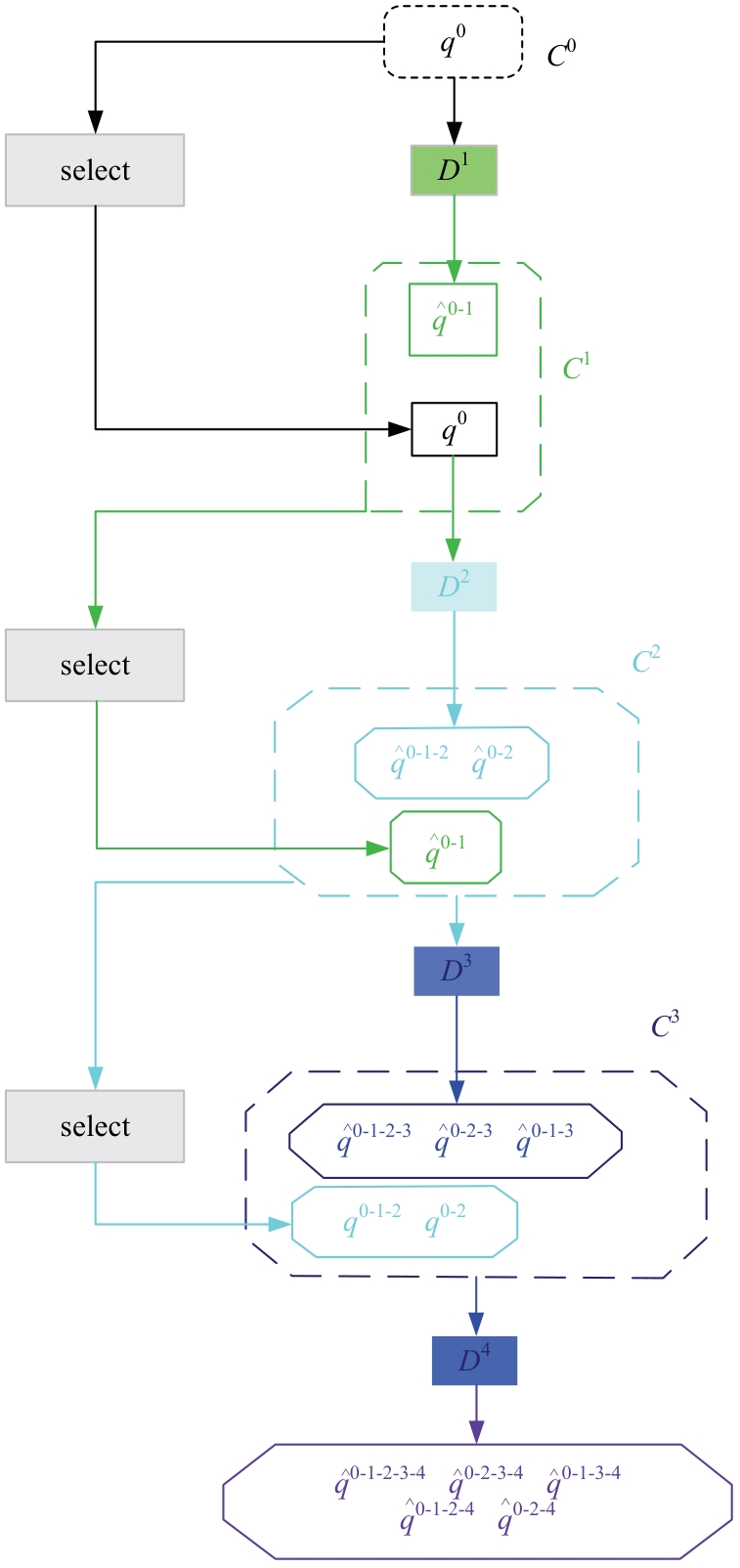
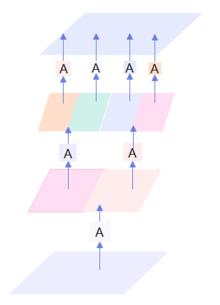
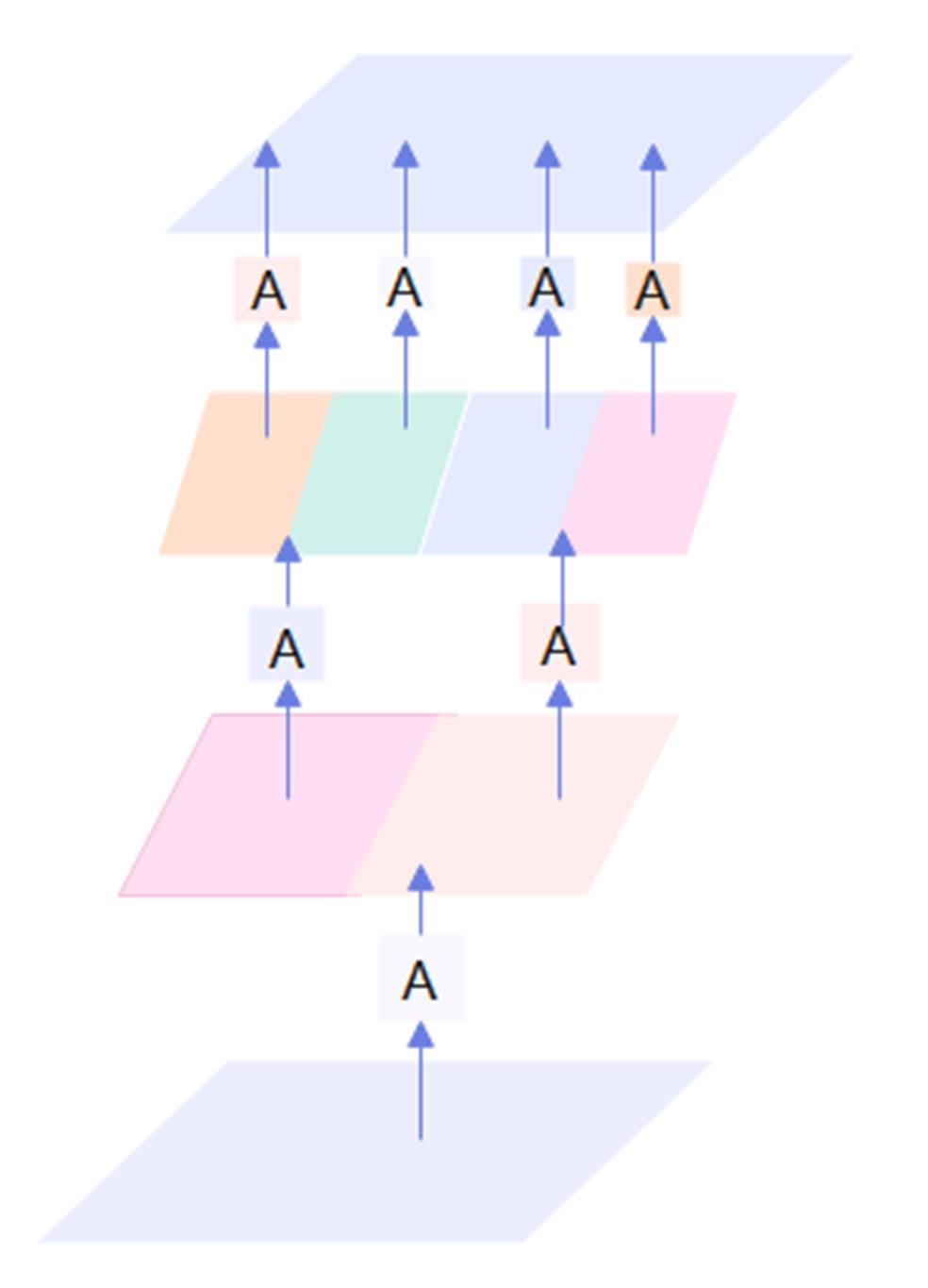
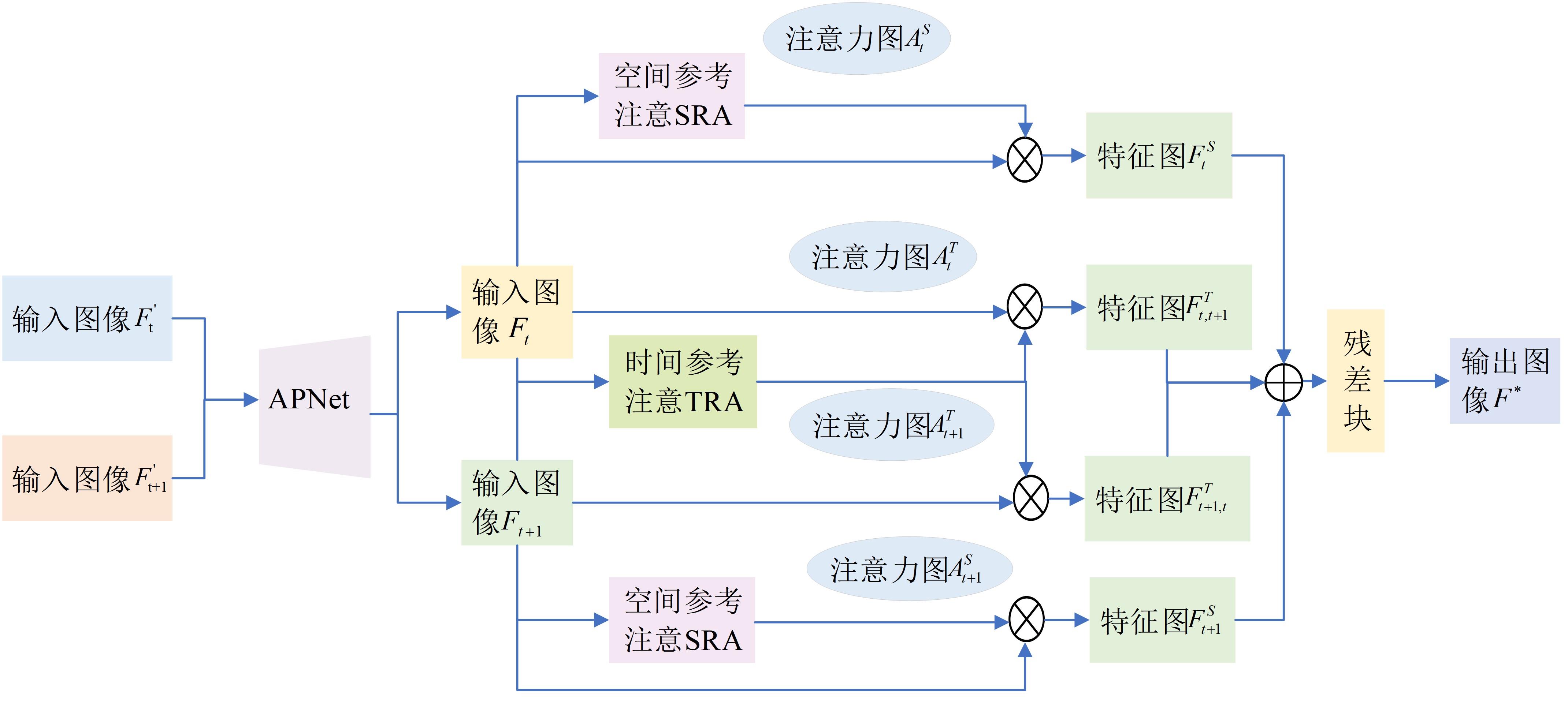
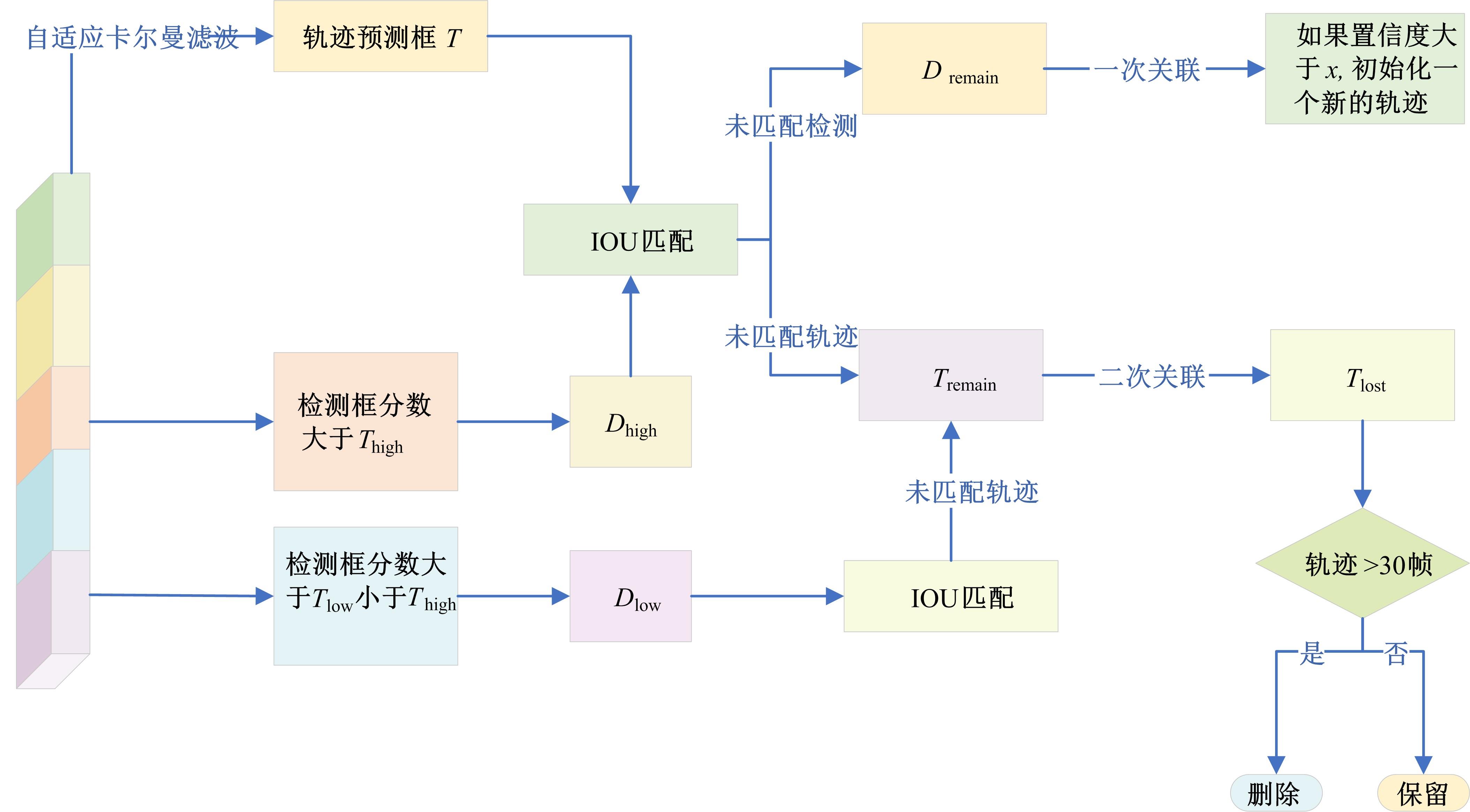
针对密集行人场景下多目标跟踪存在的目标错检、漏检、关联不准确、重识别错误等问题,提出了一种基于Transformer的多行人跟踪网络。算法包含检测、数据关联和追踪3个模块,其中检测模块采用选择性查询收集方法增强解码器对关键特征的收集,提高模型对目标的表征能力,有效减少目标错检漏检问题;数据关联模块采用双线性长短期记忆网络(BLSTM)与二次数据关联的融合策略,解决密集行人由于相似外观导致关联不准确的问题;最后在追踪模块上将注意力金字塔嵌入金字塔时空聚合模块以捕获不同尺度特征图的时空信息,提高了目标重识别的准确性。本文网络在公开数据集MOT16、MOT17上进行了性能测试,实验结果表明:相较于其他方法,本文方法能够实现更准确的多行人追踪。
中图分类号:
- TP391




| [1] | 丁贵鹏, 陶钢, 庞春桥, 等. 基于无锚的轻量化孪生网络目标跟踪算法[J]. 吉林大学学报: 理学版, 2023, 61(4): 890-898. |
| Ding Gui-peng, Tao Gang, Pang Chun-qiao, et al. Anchorless target tracking algorithm for lightweight siamese network[J]. Journal of Jilin University (Science Edition),2023,61(4):890-898. | |
| [2] | 徐涛, 马克, 刘才华. 基于深度学习的行人多目标跟踪方法[J]. 吉林大学学报: 工学版, 2021, 51(1): 27-38. |
| Xu Tao, Ma Ke, Liu Cai-hua, et al. Multi-object pedestrian tracking based on deep learning[J]. Journal of Jilin University (Engineering and Technology Edition), 2021, 51(1): 27-38. | |
| [3] | Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric[C]∥IEEE International Conference on Image Processing (ICIP), Beijing, China, 2017: 3645-3649. |
| [4] | Zhang Y, Wang C, Wang X, et al. Fairmot: on the fairness of detection and re-identification in multiple object tracking[J]. International Journal of Computer Vision, 2021, 129: 3069-3087. |
| [5] | Xu Y, Ban Y, Delorme G, et al. TransCenter: Transformers with dense representations for multiple-object tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(6): 7820-7835. |
| [6] | Zhou X, Yin T, Koltun V, et al. Global tracking transformers[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,New Orleans, USA, 2022: 8771-8780. |
| [7] | Cai J, Xu M, Li W, et al. Memot: multi-object tracking with memory[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 8090-8100. |
| [8] | Chen F, Zhang H, Hu K, et al. Enhanced training of query-based object detection via selective query recollection[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Vancouver, Canada, 2023: 23756-23765. |
| [9] | Wang Y, Zhang P, Gao S, et al. Pyramid spatial-temporal aggregation for video-based person re-identification[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision,Montreal, Canada, 2021: 12026-12035. |
| [10] | Chen G, Gu T, Lu J, et al. Person re-identification via attention pyramid[J]. IEEE Transactions on Image Processing, 2021, 30: 7663-7676. |
| [11] | Kim C, Li F X, Alotaibi M, et al. Discriminative appearance modeling with multi-track pooling for real-time multi-object tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville, USA, 2021: 9553-9562. |
| [12] | Zhang Y, Sun P, Jiang Y, et al. Bytetrack: multi-object tracking by associating every detection box[C]∥The 17th European Conference on Computer Vision,Tel Aviv, Israel, 2022: 1-21. |
| [13] | Meinhardt T, Kirillov A, Leal-Taixe L, et al. Trackformer: multi-object tracking with transformers[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,New Orleans,USA, 2022: 8844-8854. |
| [14] | Zeng F, Dong B, Zhang Y, et al. Motr: end-to-end multiple-object tracking with transformer[C]∥The 17th European Conference on Computer Vision,Tel Aviv, Israel, 2022: 659-675. |
| [15] | Sun P, Cao J, Jiang Y, et al. Transtrack: multiple object tracking with transformer[J/OL].[2023-11-20]. . |
| [16] | Zhu X, Su W, Lu L, et al. Deformable detr: deformable transformers for end-to-end object detection[J/OL]. [2023-11-21].. |
| [17] | 庄珊娜, 王君帅, 白晶, 等. 基于三维卷积与自注意力机制的视频行人重识别[J]. 吉林大学学报: 工学版, 2025, 55(7): 2409-2417. |
| Zhuang Shan-na, Wang Jun-shuai, Bai Jing, et al.Video-based person re-identification based on three-dimensional convolution and self-attention mechanism[J]. Journal of Jilin University (Engineering and Technology Edition), 2025, 55(7): 2409-2417. | |
| [28] | 涂淑琴, 黄正鑫, 梁云, 等. 改进TransTrack多目标生猪行为跟踪方法[J]. 农业工程学报, 2023, 39(15): 172-180. |
| Tu Shu-qin, Huang Zheng-xin, Liang Yun, et al.Improvement of the TransTrack multi-objective hog behavior tracking method[J]. Transactions of the Chinese Society of Agricultural Engineering, 2023,39(15): 172-180. | |
| [19] | Guo Y, Stutz D, Schiele B. Robustifying token attention for vision transformers[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 17511-17522. |
| [20] | Peng J, Wang C, Wan F, et al. Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking[C]∥Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, 2020: 145-161. |
| [21] | Wang Y, Kitani K, Weng X. Joint object detection and multi-object tracking with graph neural networks[C]∥IEEE International Conference on Robotics and Automation(ICRA), Xi'an, China, 2021: 13708-13715. |
| [22] | Pang B, Li Y, Zhang Y, et al. Tubetk: adopting tubes to track multi-object in a one-step training model[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle, USA, 2020: 6307-6317. |
| [23] | Yu F, Li W, Li Q, et al. Poi: multiple object tracking with high performance detection and appearance feature[C]∥European Conferenceon Computer Vision: amsterdam, The Netherlands, 2016: 36-42. |
| [24] | Cao J, Zhang J, Li B, et al. RetinaMOT: rethinking anchor-free YOLOv5 for online multiple object tracking[J]. Complex & Intelligent Systems, 2023, 9(5): 5115-5133. |
| [25] | Wan X, Zhou S, Wang J, et al. Multiple object tracking by trajectory map regression with temporal priors embedding[C]∥Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 2021: 1377-1386. |
| [26] | Wu J, Cao J, Song L, et al. Track to detect and segment: an online multi-object tracker[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville,USA,2021: 12347-12356. |
| [27] | Nguyen P, Quach K G, Kitani K, et al. Type-to-track: retrieve any object via prompt-based tracking[J/OL].[2023-11-20]. . |
| [28] | Mahmoudi N, Ahadi S M, Rahmati M. Multi-target tracking using CNN-based features: CNNMTT[J]. Multimedia Tools and Applications, 2019, 78(6): 7077-7096. |
| [29] | Meneses M, Matos L, Prado B, et al. Learning to associate detections for real-time multiple object tracking[J/OL]. [2023-11-22].. |
| [30] | Pang J, Qiu L, Li X, et al. Quasi-dense similarity learning for multiple object tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville, USA, 2021: 164-173. |
| [31] | Zhou X, Koltun V, Krähenbühl P. Tracking objects as points[C]∥European Conference on Computer Vision, Glasgow, UK, 2020: 474-490. |
| [1] | 庄珊娜,王君帅,白晶,杜京瑾,王正友. 基于三维卷积与自注意力机制的视频行人重识别[J]. 吉林大学学报(工学版), 2025, 55(7): 2409-2417. |
| [2] | 侯越,郭劲松,林伟,张迪,武月,张鑫. 分割可跨越车道分界线的多视角视频车速提取方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1692-1704. |
| [3] | 刘广文,赵绮莹,王超,高连宇,才华,付强. 基于渐进递归的生成对抗单幅图像去雨算法[J]. 吉林大学学报(工学版), 2025, 55(4): 1363-1373. |
| [4] | 刘广文,谢欣月,付强,才华,王伟刚,马智勇. 基于时空模板焦点注意的Transformer目标跟踪算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1037-1049. |
| [5] | 程德强,刘规,寇旗旗,张剑英,江鹤. 基于自适应大核注意力的轻量级图像超分辨率网络[J]. 吉林大学学报(工学版), 2025, 55(3): 1015-1027. |
| [6] | 才华,郑延阳,付强,王晟宇,王伟刚,马智勇. 基于多尺度候选融合与优化的三维目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(2): 709-721. |
| [7] | 姜来为,王策,杨宏宇. 基于深度学习的多目标跟踪研究进展综述[J]. 吉林大学学报(工学版), 2025, 55(11): 3429-3445. |
| [8] | 关欣,周子健,李锵. 基于图结构引导和位置信息强化的人体姿态估计[J]. 吉林大学学报(工学版), 2025, 55(10): 3283-3295. |
| [9] | 朱圣杰,王宣,徐芳,彭佳琦,王远超. 机载广域遥感图像的尺度归一化目标检测方法[J]. 吉林大学学报(工学版), 2024, 54(8): 2329-2337. |
| [10] | 才华,寇婷婷,杨依宁,马智勇,王伟刚,孙俊喜. 基于轨迹优化的三维车辆多目标跟踪[J]. 吉林大学学报(工学版), 2024, 54(8): 2338-2347. |
| [11] | 孙铭会,薛浩,金玉波,曲卫东,秦贵和. 联合时空注意力的视频显著性预测[J]. 吉林大学学报(工学版), 2024, 54(6): 1767-1776. |
| [12] | 高云龙,任明,吴川,高文. 基于注意力机制改进的无锚框舰船检测模型[J]. 吉林大学学报(工学版), 2024, 54(5): 1407-1416. |
| [13] | 王殿伟,张池,房杰,许志杰. 基于高分辨率孪生网络的无人机目标跟踪算法[J]. 吉林大学学报(工学版), 2024, 54(5): 1426-1434. |
| [14] | 王宇,赵凯. 基于亚像素定位的人体姿态热图后处理[J]. 吉林大学学报(工学版), 2024, 54(5): 1385-1392. |
| [15] | 毛琳,苏宏阳,杨大伟. 时间显著注意力孪生跟踪网络[J]. 吉林大学学报(工学版), 2024, 54(11): 3327-3337. |
|
||