吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (12): 4034-4044.doi: 10.13229/j.cnki.jdxbgxb.20240442
• 计算机科学与技术 • 上一篇
结合注意力与上下文融合的遥感图像道路提取
李云红( ),王梅,苏雪平,李丽敏,张富星,郝特吉
),王梅,苏雪平,李丽敏,张富星,郝特吉
- 西安工程大学 电子信息学院,西安 710048
Road extraction from remote sensing images combining attention and context fusion
Yun-hong LI(),Mei WANG,Xue-ping SU,Li-min LI,Fu-xing ZHANG,Te-ji HAO
- School of Electronics and Information,Xi'an Polytechnic University,Xi'an 710048,China
摘要:
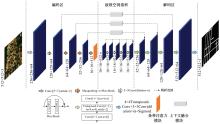
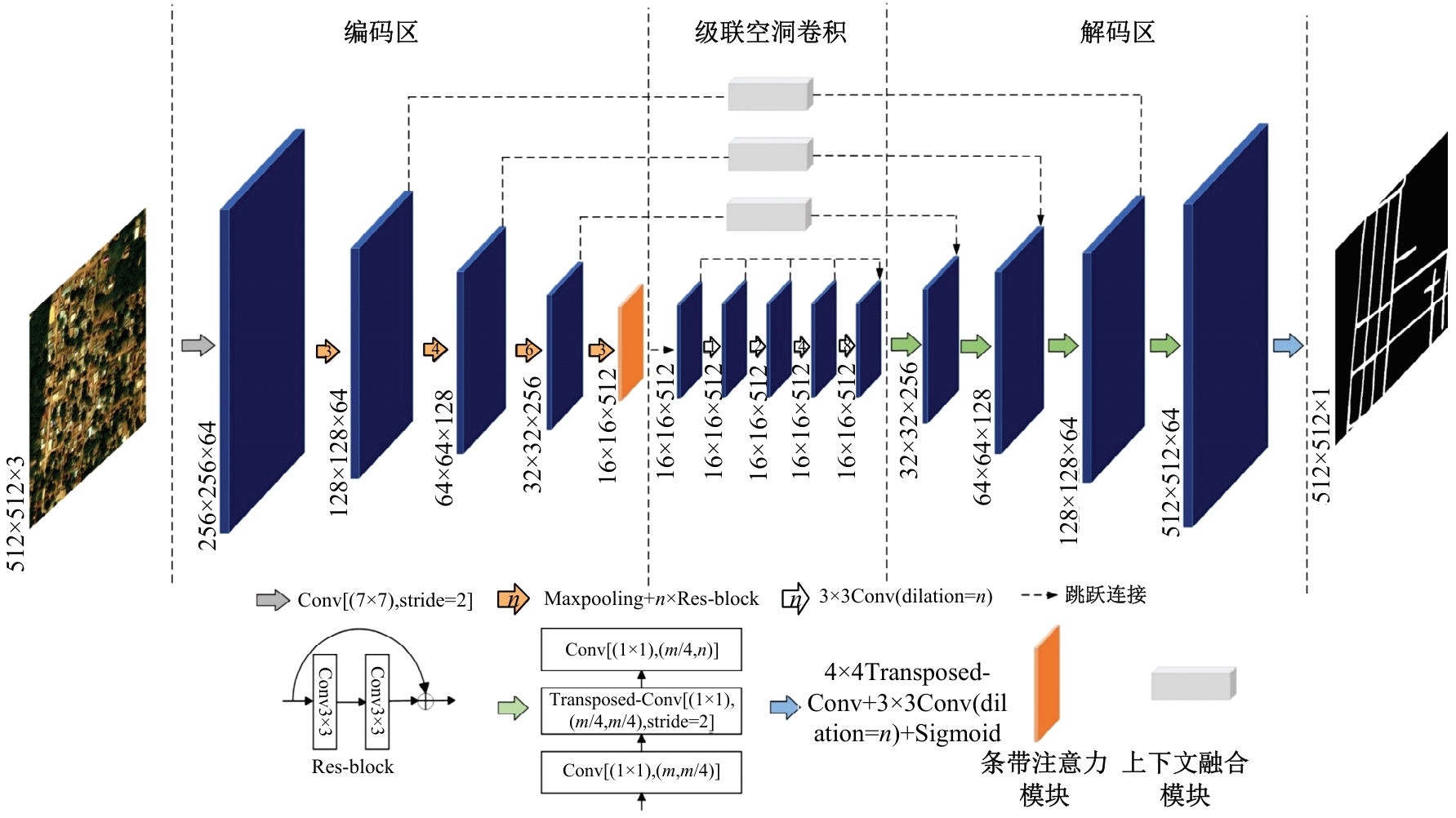
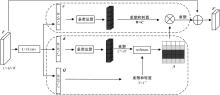
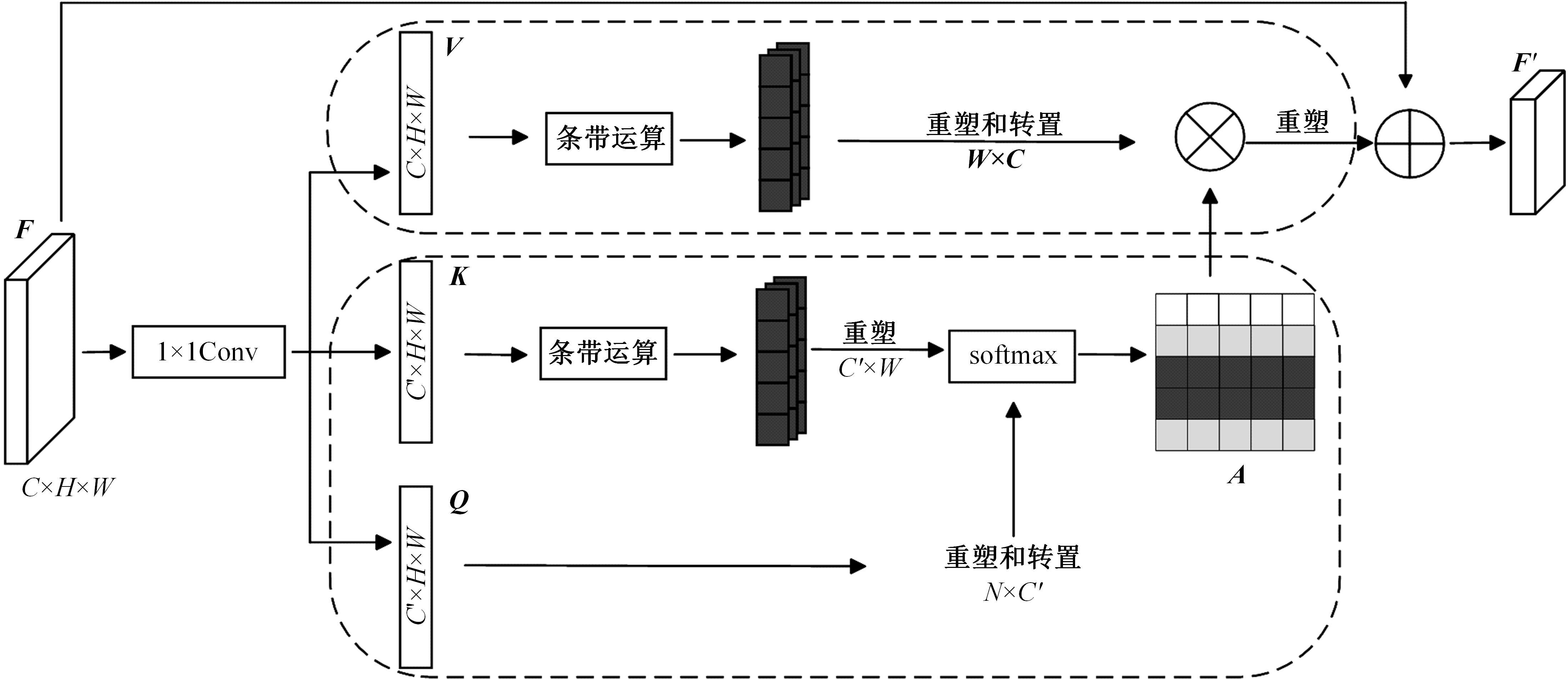
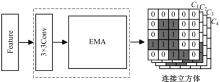
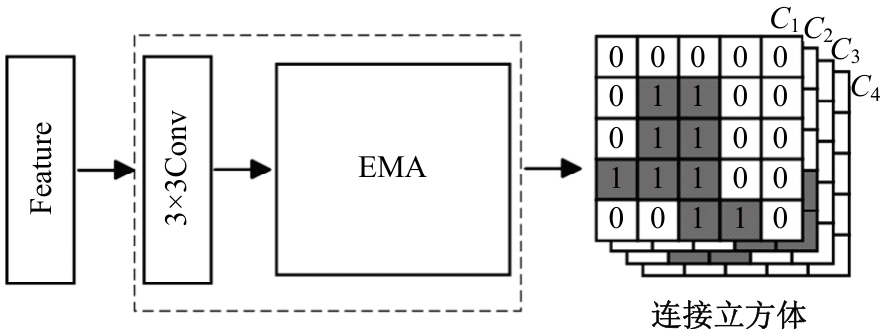
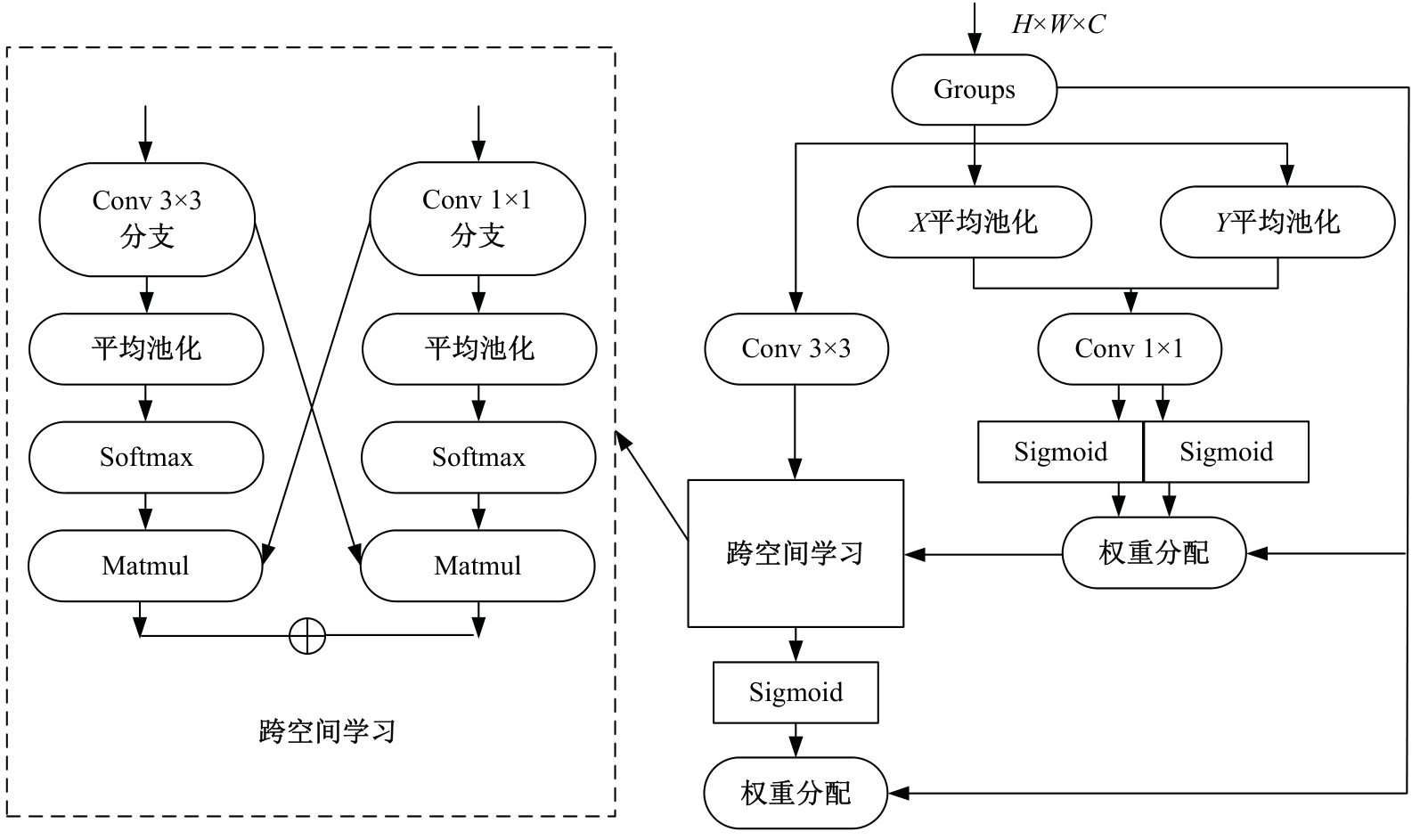
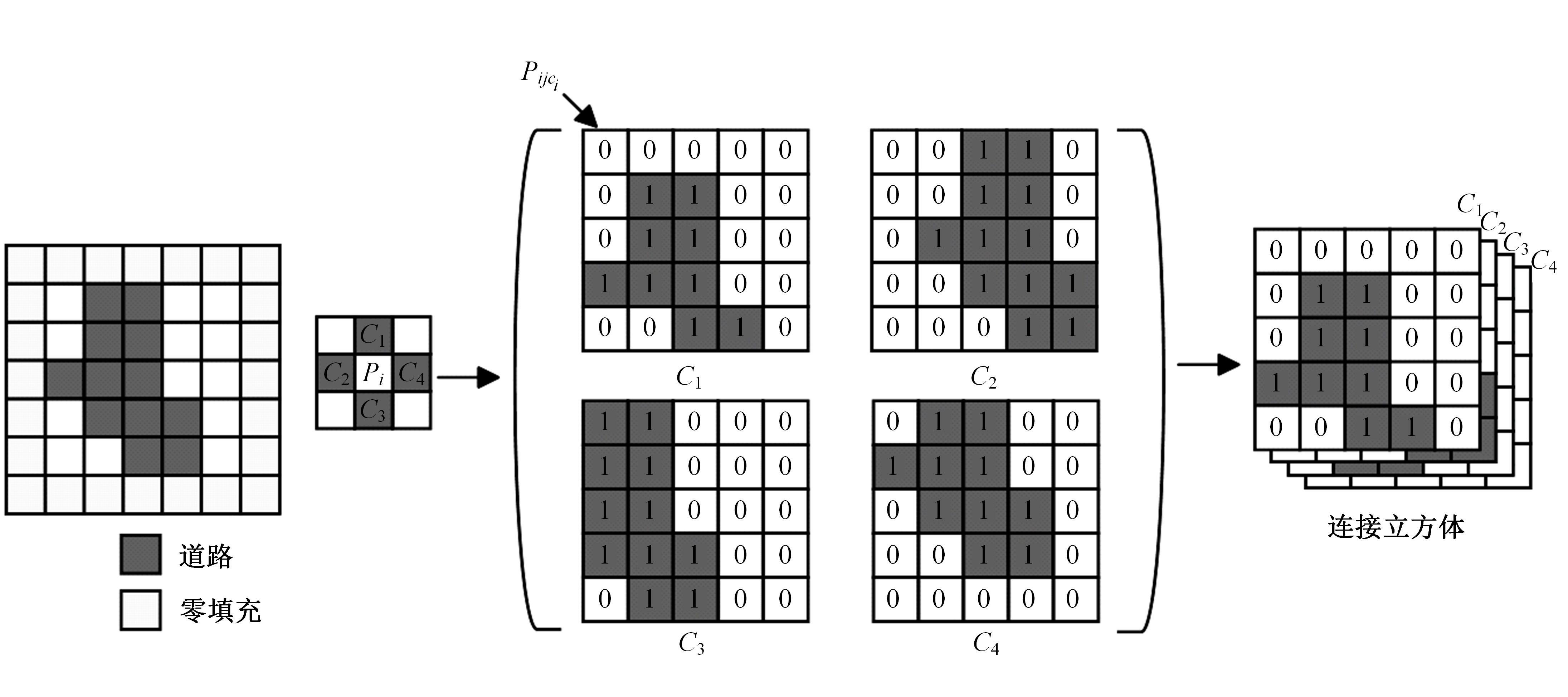
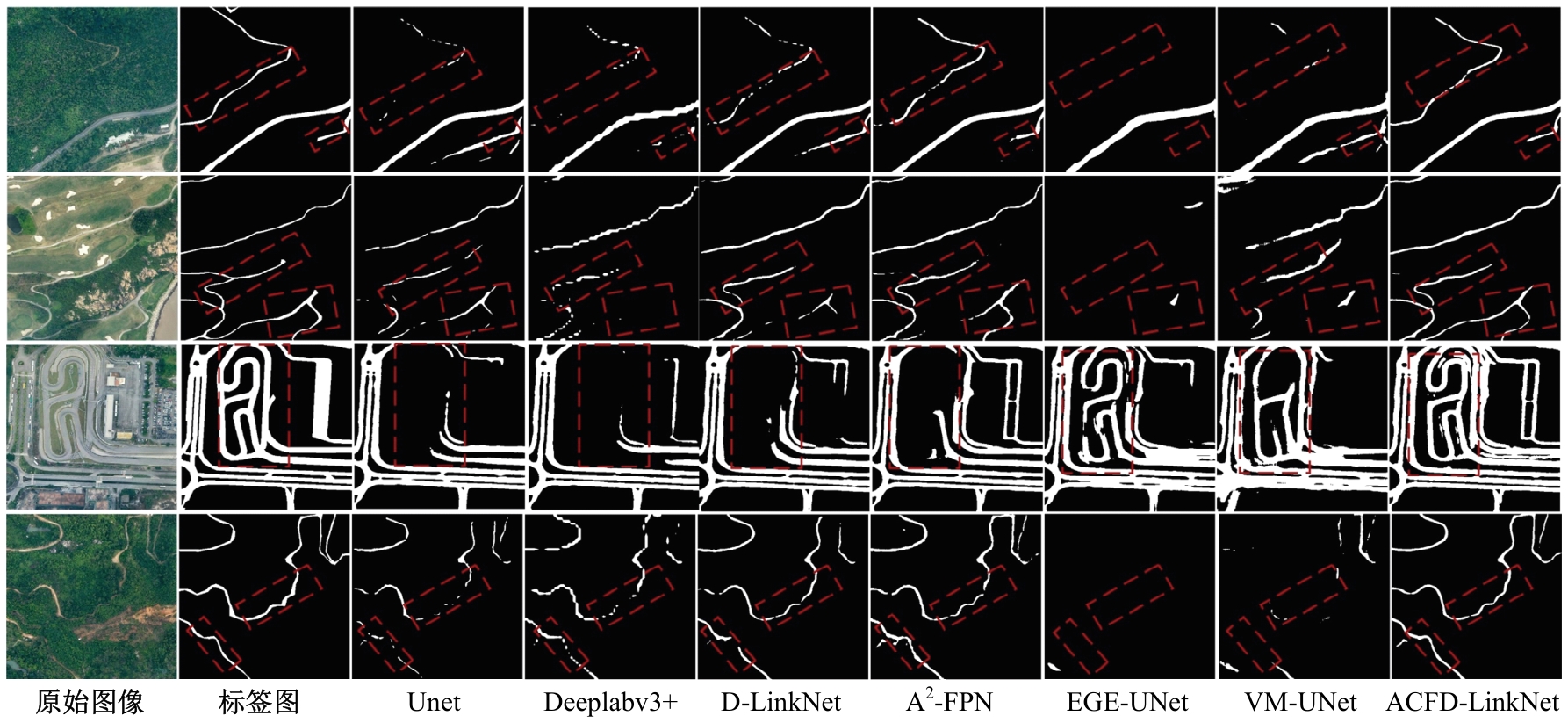
针对遥感图像地物复杂,道路存在细长、连续分布且易受遮挡的问题,提出了一种结合注意力与上下文融合的遥感图像道路提取模型(ACFD-LinkNet)。该模型以D-LinkNet网络为基础,首先在D-LinkNet网络编码器最后卷积层后采用条带注意力模块增强不同尺度道路的特征提取能力,更好地捕捉道路的全局特征,捕获道路的长距离信息;其次,提出了一种上下文融合模块(CFM),并添加至网络编解码的特征传递部分预测相邻像素之间的道路连接,融合上下文不同层级之间的道路信息,解决障碍物遮挡干扰道路连接的问题;最后,对改进模型的交叉熵损失函数和Dice损失函数设置多损失函数超参数权重分配,解决数据集正负样本不均的问题,通过调整权重比值获取最佳分割精度。在DeepGlobe和CHN6-CUG数据集上进行实验,综合指标F1值分别达到86.76%、92.12%,相比D-LinkNet模型分别提高了3.96%、1.13%。此外,相较于Unet、Deeplabv3+、A2-FPN等网络,本文模型有最优的性能表现。
中图分类号:
- TP751







| [1] | Chen R, Li X, Hu Y, et al. Road extraction from remote sensing images in wildland-urban interface areas[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 19: 1-5. |
| [2] | Zhao K, Liu J, Wang Q, et al. Road damage detection from post-disaster high-resolution remote sensing images based on tld framework[J]. IEEE Access, 2022, 10: 43552-43561. |
| [3] | Zhang X, Jiang Y, Wang L, et al. Complex mountain road extraction in high-resolution remote sensing images via a light roadformer and a new benchmark[J]. Remote Sensing, 2022, 14(19): No.4729. |
| [4] | 宦海, 盛宇, 顾晨曦. 基于遥感图像道路提取的全局指导多特征融合网络[J]. 浙江大学学报: 工学版, 2024, 58(4): 696-707. |
| Huan Hai, Sheng Yu, Gu Chen-xi.Global guidance multi-feature fusion networ kbased on remote sensing image road extraction[J]. Journal of Zhejiang University(Engineering Science Edition), 2024, 58(4):696-707. | |
| [5] | 谭国金, 欧吉, 艾永明, 等. 基于改进DeepLabv3+模型的桥梁裂缝图像分割方法[J]. 吉林大学学报: 工学版, 2024, 54(1): 173-179. |
| Tan Guo-jin, Ji Ou, Ai Yong-ming, et al. Bridge crack image segmentation method based on improved DeepLabv3+ model[J]. Journal of Jilin University (Engineering and Technology Edition), 2024,54(1):173-179. | |
| [6] | 刘洋, 毛克明. 基于自适应反馈机制的小差异化图像纹理特征信息数据检索[J]. 江苏大学学报: 自然科学版, 2025, 46(1): 73-81. |
| Liu Yang, Mao Ke-ming. Retrieval of texture feature information data for small differentiated images based on adaptive feedback mechanism[J]. Journal of Jiangsu University(Natural Science Edition), 2025, 46(1): 73-81. | |
| [7] | 杨洋, 何童瑶, 詹永照, 等. 基于软聚类的深度图增强方法[J]. 江苏大学学报: 自然科学版, 2024, 45(2): 183-190. |
| Yang Yang, He Tong-yao, Zhan Yong-zhao, et al. Depth image enhancement method based on soft clustering[J]. Journal of Jiangsu University(Natural Science Edition), 2024, 45(2): 183-190. | |
| [8] | Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston,USA,2015: 3431-3440. |
| [9] | Wang S, Mu X, Yang D, et al. Road extraction from remote sensing images using the inner convolution integrated encoder-decoder network and directional conditional random fields[J]. Remote Sensing, 2021, 13(3): No.465. |
| [10] | Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]∥18th International Conference on Medical Image Computing and Computer-assisted Intervention-MICCAI, Munich, Germany, 2015: 234-241. |
| [11] | Zhou L, Zhang C, Wu M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City,USA, 2018: 182-186. |
| [12] | Chaurasia A, Culurciello E. Linknet: Exploiting encoder representations for efficient semantic segmentation[C]∥2017 IEEE Visual Communications and Image Processing, St. Petersburg,USA,2017: 1-4. |
| [13] | Wu K, Cai F. Dual Attention D-LinkNet for road segmentation in remote sensing images[C]∥2022 IEEE 14th International Conference on Advanced Infocomm Technology, Chongqing, China,2022: 304-307. |
| [14] | Kampffmeyer M, Dong N, Liang X, et al. ConnNet: a long-range relation-aware pixel-connectivity network for salient segmentation[J]. IEEE Transactions on Image Processing, 2018, 28(5): 2518-2529. |
| [15] | Maji D, Sigedar P, Singh M. Attention Res-UNet with guided decoder for semantic segmentation of brain tumors[J]. Biomedical Signal Processing and Control, 2022, 71: No.103077. |
| [16] | Dai L, Zhang G, Zhang R. RADANet: road augmented deformable attention network for road extraction from complex high-resolution remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-13. |
| [17] | Song Q, Mei K, Huang R. AttaNet: Attention-augmented network for fast and accurate scene parsing[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, Menlo Park,USA,2021, 35(3): 2567-2575. |
| [18] | Ouyang D, He S, Zhang G, et al. Efficient multi-scale attention module with cross-spatial learning[C]∥ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island,Greece,2023: 1-5. |
| [19] | Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]∥Proceedings of the European Conference on Computer Vision, Munich,Germany,2018: 801-818. |
| [20] | Zhou G, Chen W, Gui Q, et al. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 1-15. |
| [21] | Li R, Wang L, Zhang C, et al. A2-FPN for semantic segmentation of fine-resolution remotely sensed images[J]. International Journal of Remote Sensing, 2022, 43(3): 1131-1155. |
| [22] | Ruan J, Xie M, Gao J, et al. Ege-unet: an efficient group enhanced unet for skin lesion segmentation[C]∥International Conference on Medical Image Computing and Computer-Assisted Intervention,Vancouver,Canada,2023: 481-490. |
| [23] | Ruan J, Xiang S. Vm-unet: Vision mamba unet for medical image segmentation[J/OL].[2024-03-25]. |
| [1] | 霍震,金立生,华强,贺阳. 基于边缘特征引导的智能汽车语义分割方法[J]. 吉林大学学报(工学版), 2025, 55(9): 3032-3041. |
| [2] | 李文辉,杨晨. 基于对比学习文本感知的小样本遥感图像分类[J]. 吉林大学学报(工学版), 2025, 55(7): 2393-2401. |
| [3] | 庄珊娜,王君帅,白晶,杜京瑾,王正友. 基于三维卷积与自注意力机制的视频行人重识别[J]. 吉林大学学报(工学版), 2025, 55(7): 2409-2417. |
| [4] | 安金岚,王澜斌,周松,黄研清. 激光沉积修复钛合金热影响区异质结构及后续热处理的性能[J]. 吉林大学学报(工学版), 2025, 55(6): 1931-1939. |
| [5] | 于营,王春平,寇人可,杨博雄,王雷,赵福军,付强. 多时相高分辨率卫星遥感图像语义分割算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2131-2137. |
| [6] | 冯志刚,王首起,于明月. 基于变分模态提取及轻量级网络的滚动轴承故障诊断[J]. 吉林大学学报(工学版), 2025, 55(6): 1883-1891. |
| [7] | 田丽,贾煜辉. 改进YOLOv5s算法的高光谱遥感图像目标检测[J]. 吉林大学学报(工学版), 2025, 55(5): 1742-1748. |
| [8] | 薛雅丽,俞潼安,崔闪,周李尊. 基于级联嵌套U-Net的红外小目标检测[J]. 吉林大学学报(工学版), 2025, 55(5): 1714-1721. |
| [9] | 张河山,范梦伟,谭鑫,郑展骥,寇立明,徐进. 基于改进YOLOX的无人机航拍图像密集小目标车辆检测[J]. 吉林大学学报(工学版), 2025, 55(4): 1307-1318. |
| [10] | 聂为之,尹斐,苏毅珊. 任务驱动下成像声呐水下目标识别方法综述[J]. 吉林大学学报(工学版), 2025, 55(4): 1163-1175. |
| [11] | 才华,王玉瑶,付强,马智勇,王伟刚,张晨洁. 基于注意力机制和特征融合的语义分割网络[J]. 吉林大学学报(工学版), 2025, 55(4): 1384-1395. |
| [12] | 张兰芳,李根泽,刘婷宇,余博. 局部多车影响下跟驰行为机理及建模[J]. 吉林大学学报(工学版), 2025, 55(3): 963-973. |
| [13] | 李扬,李现国,苗长云,徐晟. 基于双分支通道先验和Retinex的低照度图像增强算法[J]. 吉林大学学报(工学版), 2025, 55(3): 1028-1036. |
| [14] | 杨燕,沈汪良. 多尺度细节增强与分层抑噪的图像去雾算法[J]. 吉林大学学报(工学版), 2025, 55(12): 4010-4023. |
| [15] | 王祥,谭国真,彭衍飞,任浩,李健平. 基于语言推理和认知记忆的自动驾驶决策模型[J]. 吉林大学学报(工学版), 2025, 55(12): 3918-3927. |
|
||