吉林大学学报(工学版) ›› 2022, Vol. 52 ›› Issue (11): 2718-2727.doi: 10.13229/j.cnki.jdxbgxb20210412
• 通信与控制工程 • 上一篇
一种多感知多约束奖励机制的驾驶策略学习方法
王忠立( ),王浩,申艳,蔡伯根
),王浩,申艳,蔡伯根
- 北京交通大学 电子信息工程学院,北京 100044
A driving decision⁃making approach based on multi⁃sensing and multi⁃constraints reward function
Zhong-li WANG(),Hao WANG,Yan SHEN,Bai-gen CAI
- School of Electronic of Information Engineering,Beijing Jiaotong University,Beijing 100044,China
摘要:
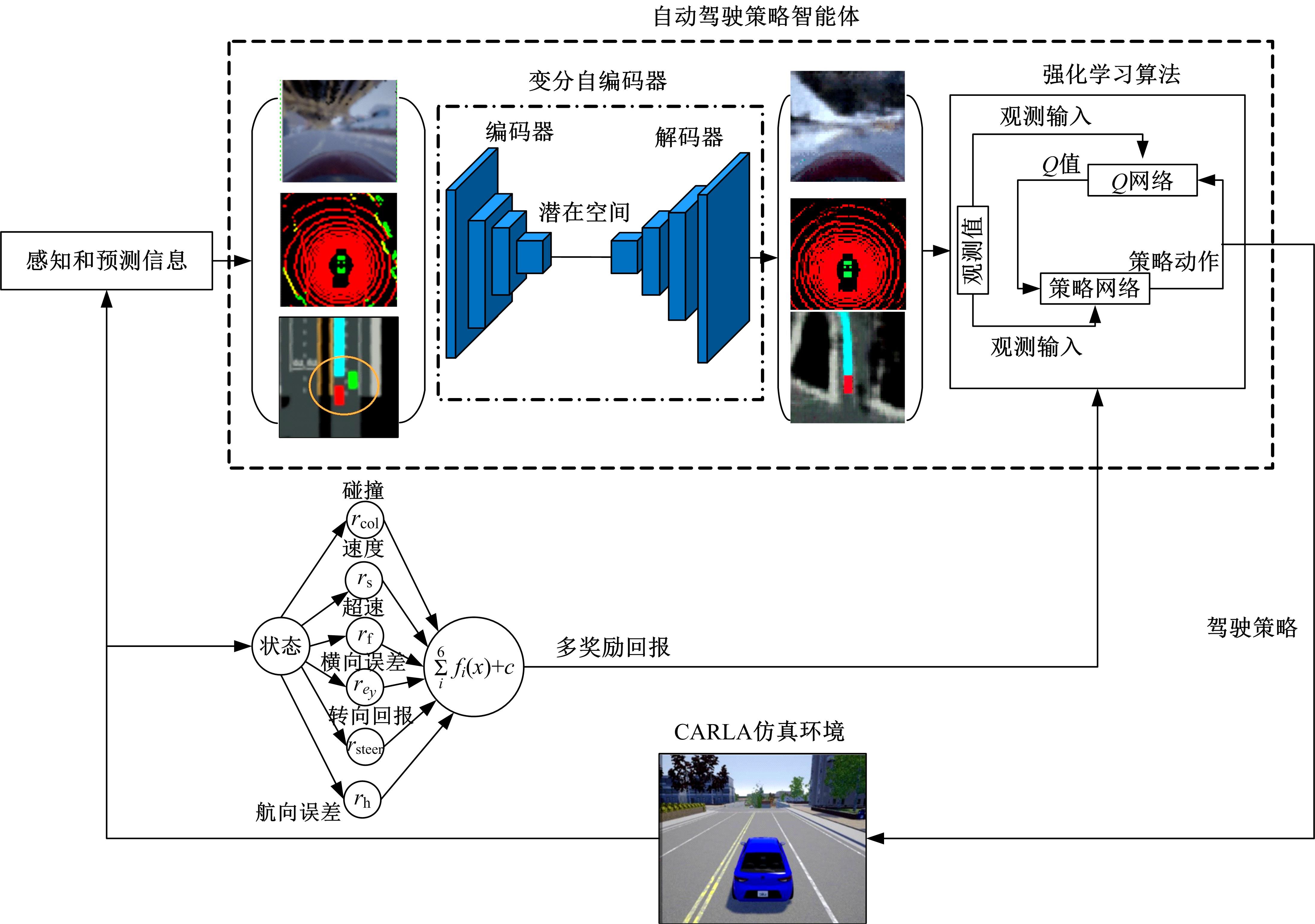
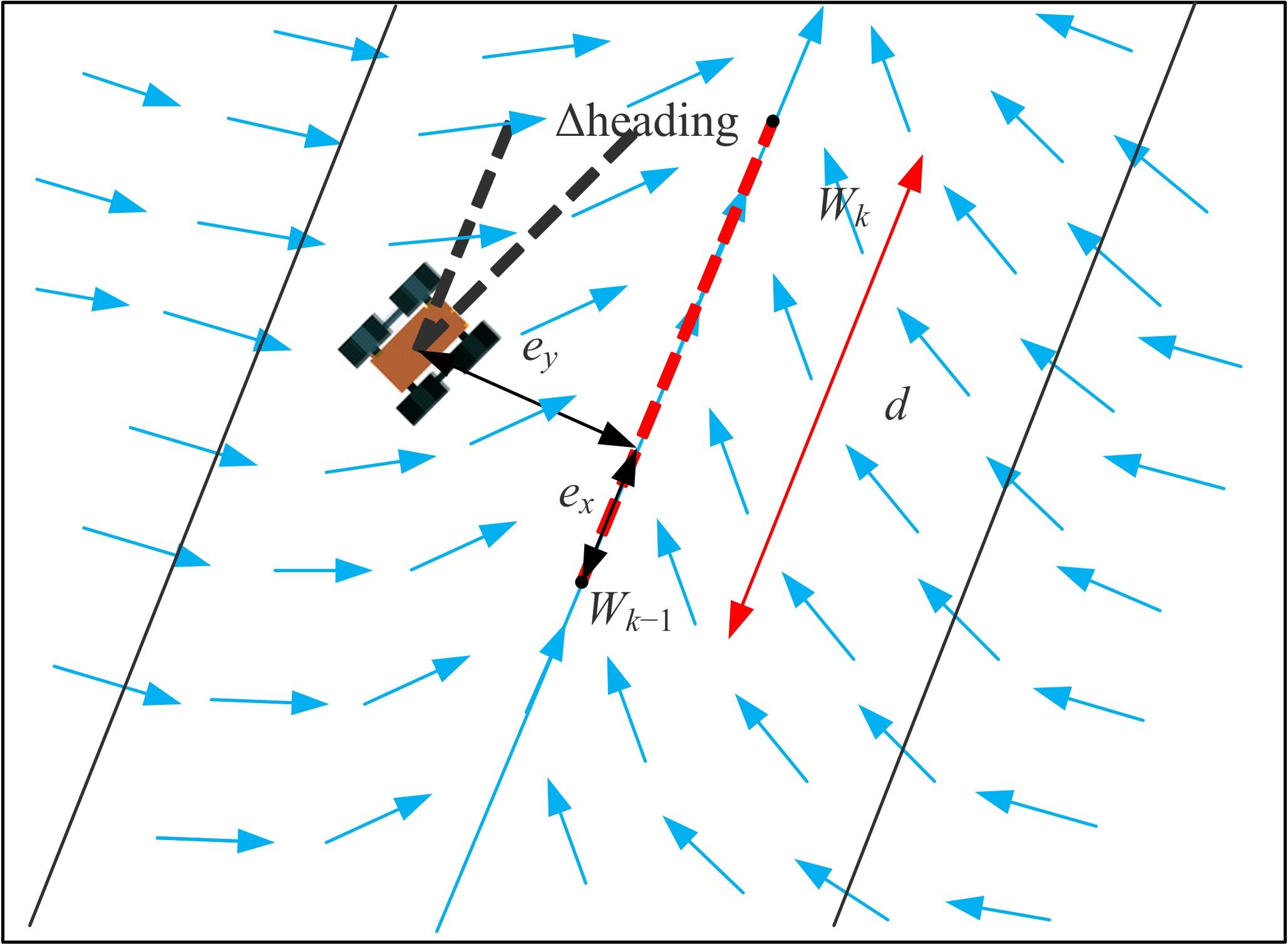
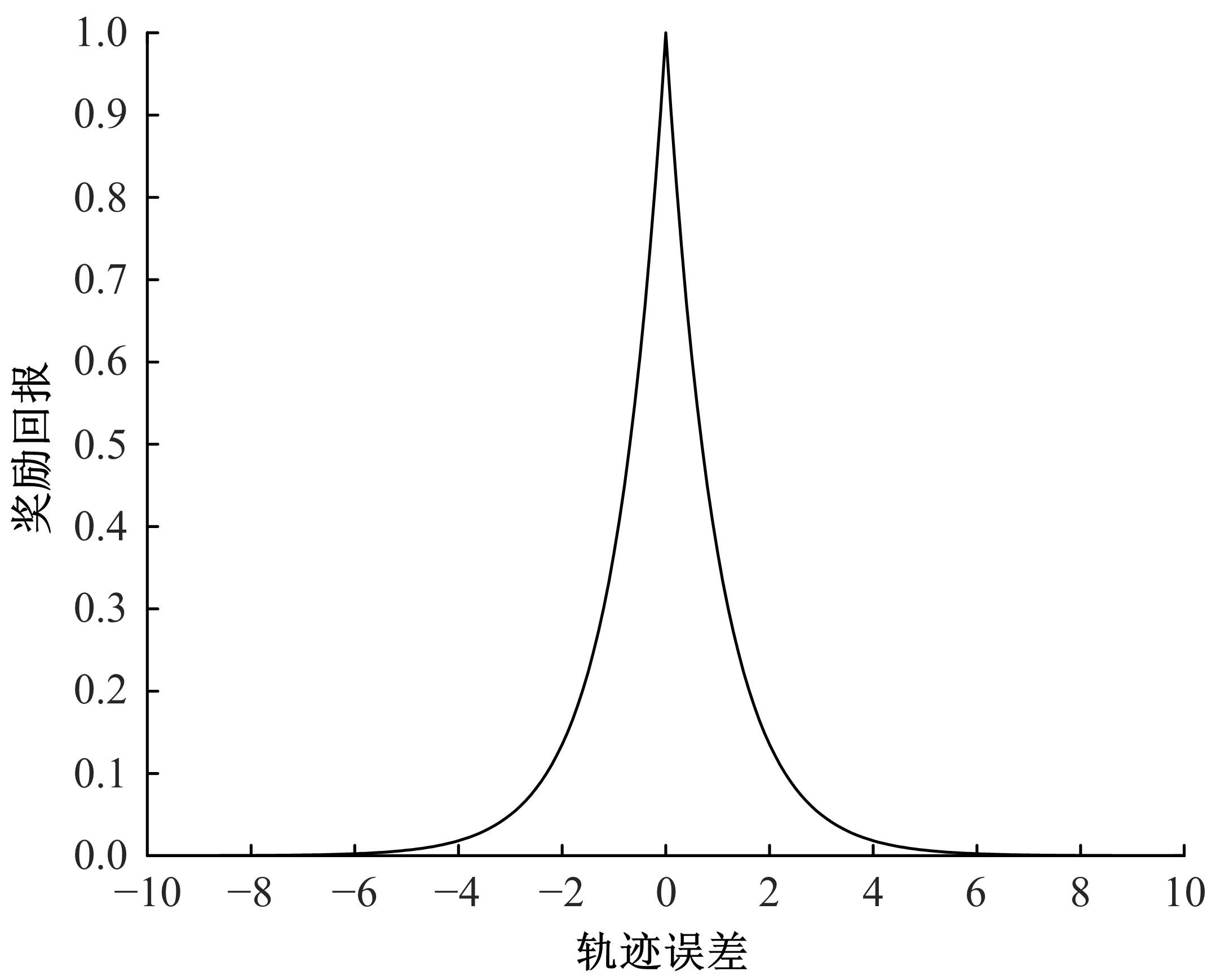
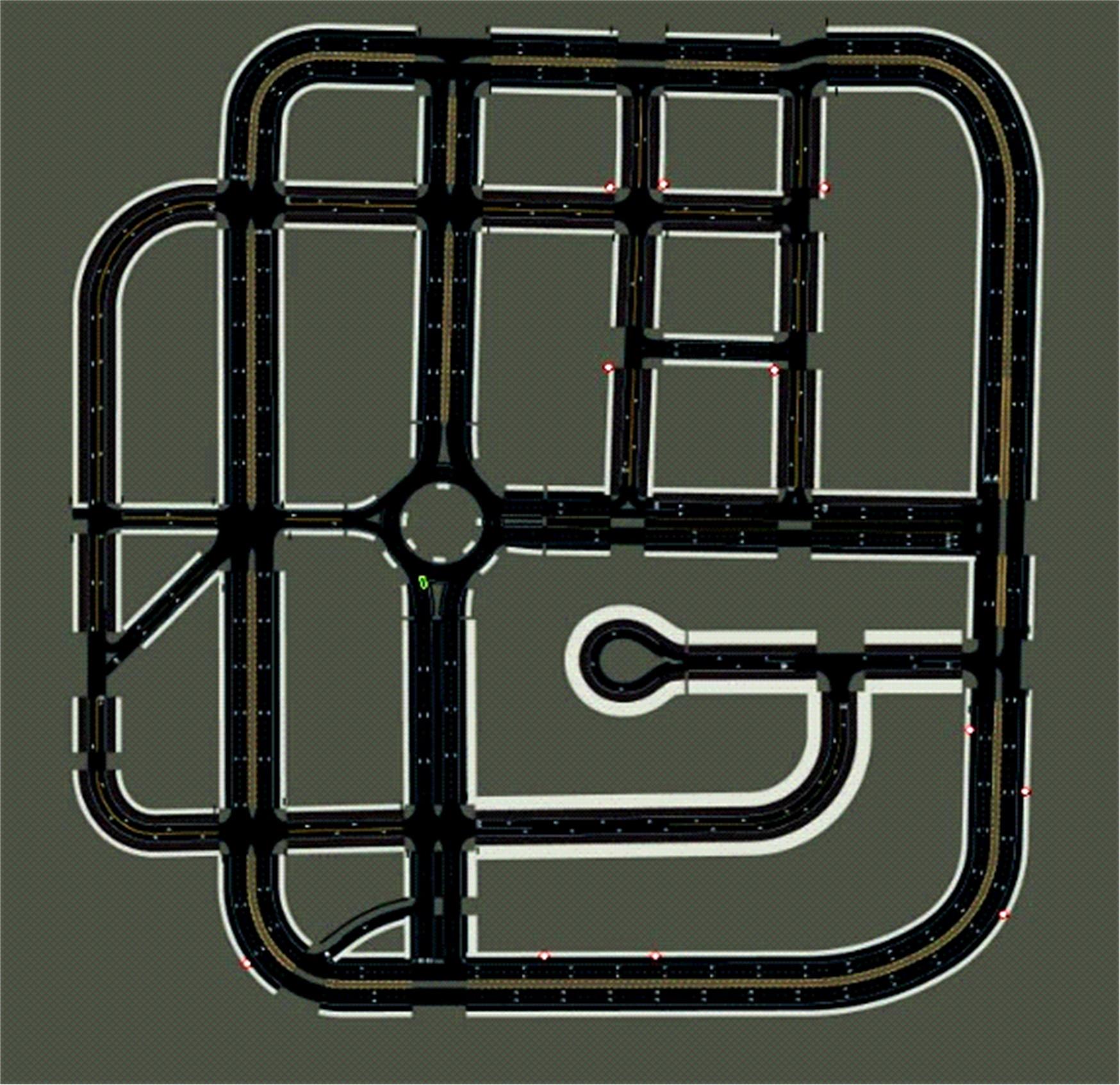
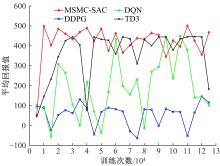
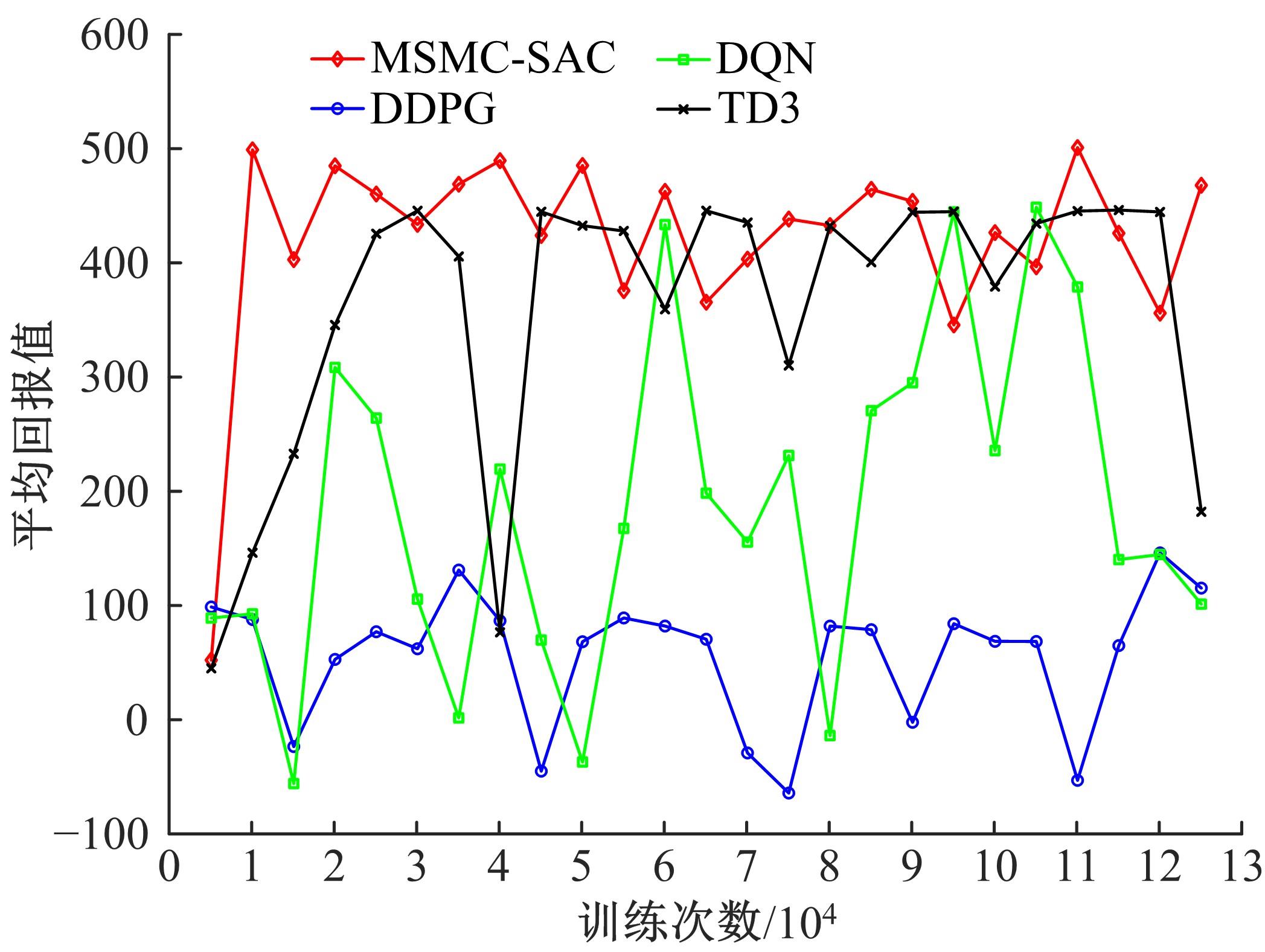
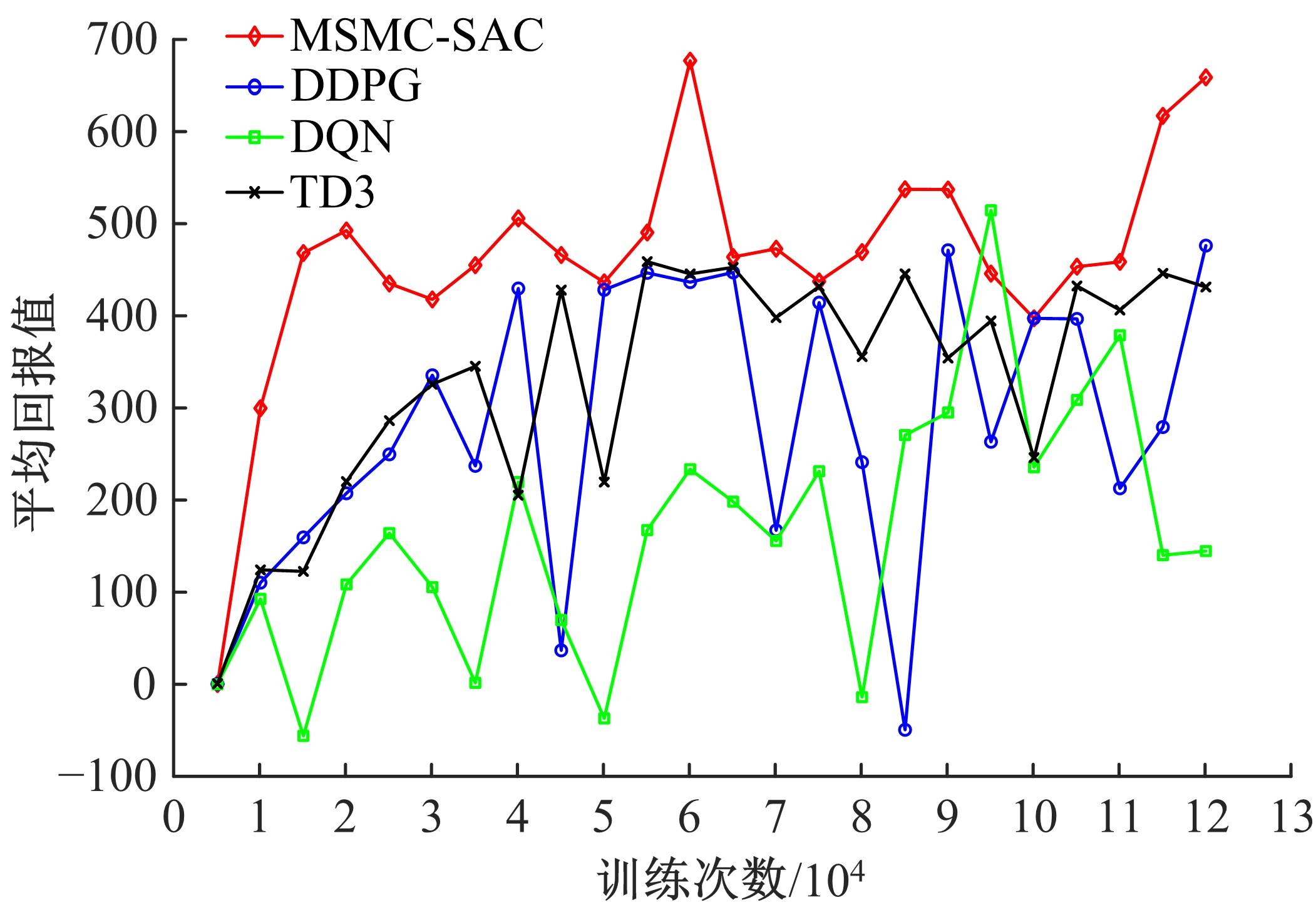
针对交通场景的复杂性和多变性,深度学习算法和深度强化学习方法适应性较差的问题,本文提出一种基于多感知输入多约束奖励函数的深度强化学习方法。方法的输入包括前视图像和激光雷达数据和鸟瞰图信息,多种输入信息经过编码网络得到潜在空间表示,经过重构后作为驾驶策略学习的输入,并在奖励函数的设计中综合考虑了横纵向误差、航向、平稳性、速度等多种约束,从而有效提高了场景的适应能力和策略学习的收敛速度。在仿真环境CARLA下搭建了典型的交通场景对方法的性能进行了仿真验证,并对多约束奖励机制进行了分析对比。结果表明:本文方法能实现车辆在多场景下的驾驶决策,性能明显优于同类SOTA方法。
中图分类号:
- U469.79
















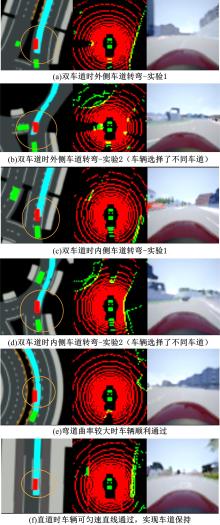
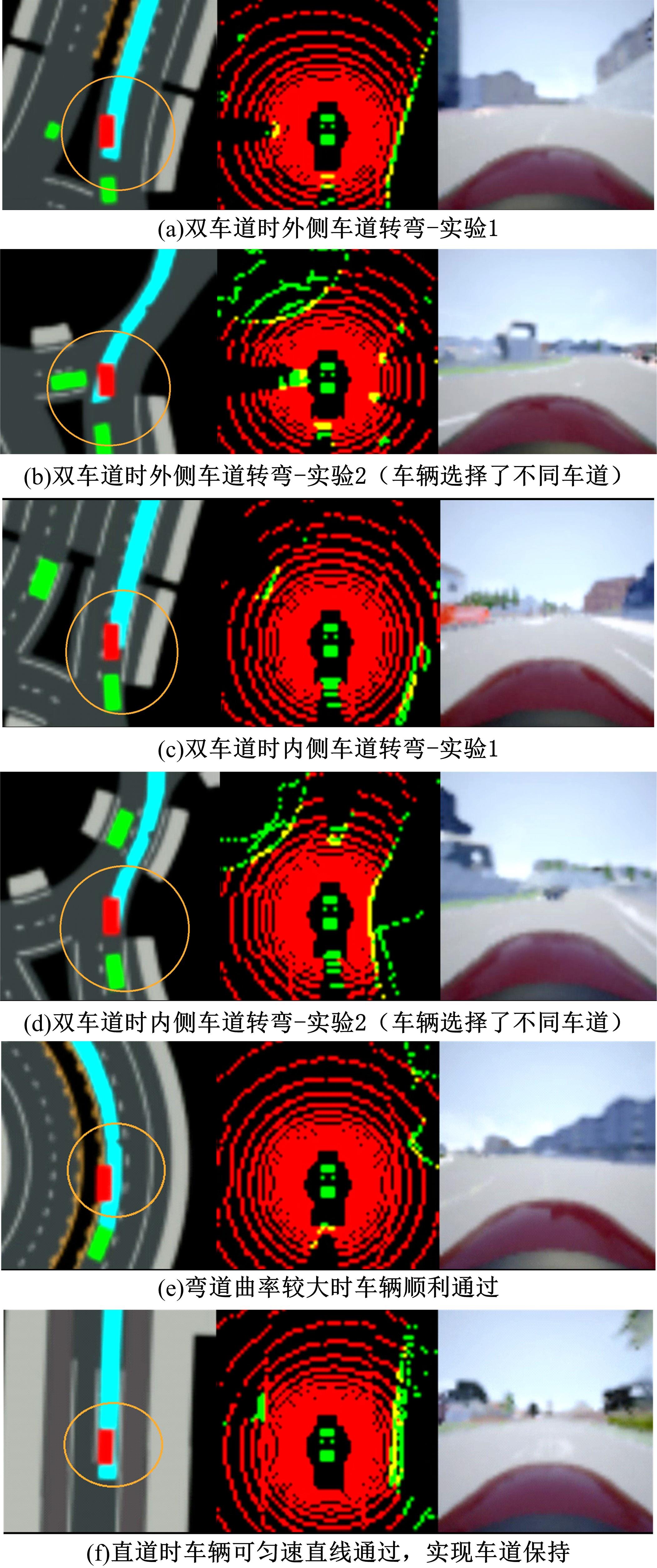


| 1 | 杨顺, 蒋渊德, 吴坚, 等. 基于多类型传感数据的自动驾驶深度强化学习方法[J]. 吉林大学学报: 工学版, 2019, 49(4): 1026-1033. |
| Yang Shun, Jiang Yuan⁃de, Wu Jian, et al. Autonomous driving policy learning based on deep reinforcement learning and multi⁃type sensor data[J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(4): 1026-1033. | |
| 2 | Silver D, Bagnell J A, Stentz A. Learning from demonstration for autonomous navigation in complex unstructured terrain[J]. The International Journal of Robotics Research, 2010, 29(12): 1565-1592. |
| 3 | Lange S, Riedmiller M, Voigtländer A. Autonomous reinforcement learning on raw visual input data in a real world application[C]∥The 2012 International Joint Conference on Neural Networks, Brisbane, Australia, 2012: 1-8. |
| 4 | Yu A, Palefsky-Smith R, Bedi R. Deep reinforcement learning for simulated autonomous vehicle control[J/OL]. [2020-08-04]. |
| 5 | Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[J/OL]. [2021-09-09]. |
| 6 | Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[J/OL]. [2018-01-04]. |
| 7 | Bansal M, Krizhevsky A, Ogale A. Chauffeurnet: learning to drive by imitating the best and synthesizing the worst[J/OL]. [2020-12-07]. .48550/arXiv.1812.03079 |
| 8 | Kingma D P, Welling M. Auto-encoding variational bayes[J/OL]. [2020-12-20]. 50/arXiv.1312.6114 |
| 9 | Woo J, Yu C, Kim N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle[J]. Ocean Engineering, 2019, 183: 155-166. |
| 10 | Dosovitskiy A, Ros G, Codevilla F, et al. CARLA: an open urban driving simulator[J/OL]. [2020-11-10]. |
| 11 | Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J/OL]. [2022-10-31]. |
| [1] | 王克勇,鲍大同,周苏. 基于数据驱动的车用燃料电池故障在线自适应诊断算法[J]. 吉林大学学报(工学版), 2022, 52(9): 2107-2118. |
| [2] | 曹起铭,闵海涛,孙维毅,于远彬,蒋俊宇. 质子交换膜燃料电池低温启动水热平衡特性[J]. 吉林大学学报(工学版), 2022, 52(9): 2139-2146. |
| [3] | 隗海林,王泽钊,张家祯,刘洋. 基于Avl-Cruise的燃料电池汽车传动比及能量管理策略[J]. 吉林大学学报(工学版), 2022, 52(9): 2119-2129. |
| [4] | 刘岩,丁天威,王宇鹏,都京,赵洪辉. 基于自适应控制的燃料电池发动机热管理策略[J]. 吉林大学学报(工学版), 2022, 52(9): 2168-2174. |
| [5] | 李丞,景浩,胡广地,刘晓东,冯彪. 适用于质子交换膜燃料电池系统的高阶滑模观测器[J]. 吉林大学学报(工学版), 2022, 52(9): 2203-2212. |
| [6] | 张佩,王志伟,杜常清,颜伏伍,卢炽华. 车用质子交换膜燃料电池空气系统过氧比控制方法[J]. 吉林大学学报(工学版), 2022, 52(9): 1996-2003. |
| [7] | 池训逞,侯中军,魏伟,夏增刚,庄琳琳,郭荣. 基于模型的质子交换膜燃料电池系统阳极气体浓度估计技术综述[J]. 吉林大学学报(工学版), 2022, 52(9): 1957-1970. |
| [8] | 裴尧旺,陈凤祥,胡哲,翟双,裴冯来,张卫东,焦杰然. 基于自适应LQR控制的质子交换膜燃料电池热管理系统温度控制[J]. 吉林大学学报(工学版), 2022, 52(9): 2014-2024. |
| [9] | 胡广地,景浩,李丞,冯彪,刘晓东. 基于高阶燃料电池模型的多目标滑模控制[J]. 吉林大学学报(工学版), 2022, 52(9): 2182-2191. |
| [10] | 陈凤祥,伍琪,李元松,莫天德,李煜,黄李平,苏建红,张卫东. 2.5吨燃料电池混合动力叉车匹配、仿真及优化[J]. 吉林大学学报(工学版), 2022, 52(9): 2044-2054. |
| [11] | 武小花,余忠伟,朱张玲,高新梅. 燃料电池公交车模糊能量管理策略[J]. 吉林大学学报(工学版), 2022, 52(9): 2077-2084. |
| [12] | 高青,王浩东,刘玉彬,金石,陈宇. 动力电池应急冷却喷射模式实验分析[J]. 吉林大学学报(工学版), 2022, 52(8): 1733-1740. |
| [13] | 王奎洋,何仁. 基于支持向量机的制动意图识别方法[J]. 吉林大学学报(工学版), 2022, 52(8): 1770-1776. |
| [14] | 王骏骋,吕林峰,李剑敏,任洁雨. 分布驱动电动汽车电液复合制动最优滑模ABS控制[J]. 吉林大学学报(工学版), 2022, 52(8): 1751-1758. |
| [15] | 刘汉武,雷雨龙,阴晓峰,付尧,李兴忠. 增程式电动汽车增程器多点控制策略优化[J]. 吉林大学学报(工学版), 2022, 52(8): 1741-1750. |
|
||