吉林大学学报(工学版) ›› 2022, Vol. 52 ›› Issue (10): 2428-2437.doi: 10.13229/j.cnki.jdxbgxb20210630
• 计算机科学与技术 • 上一篇
基于多尺度特征融合及双重注意力机制的自监督三维人脸重建
周大可( ),张超,杨欣
),张超,杨欣
- 南京航空航天大学 自动化学院,南京 211100
Self-supervised 3D face reconstruction based on multi-scale feature fusion and dual attention mechanism
Da-ke ZHOU(),Chao ZHANG,Xin YANG
- College of Automation Engineering,Nanjing University of Aeronautics and Astronautics,Nanjing 211100,China
摘要:
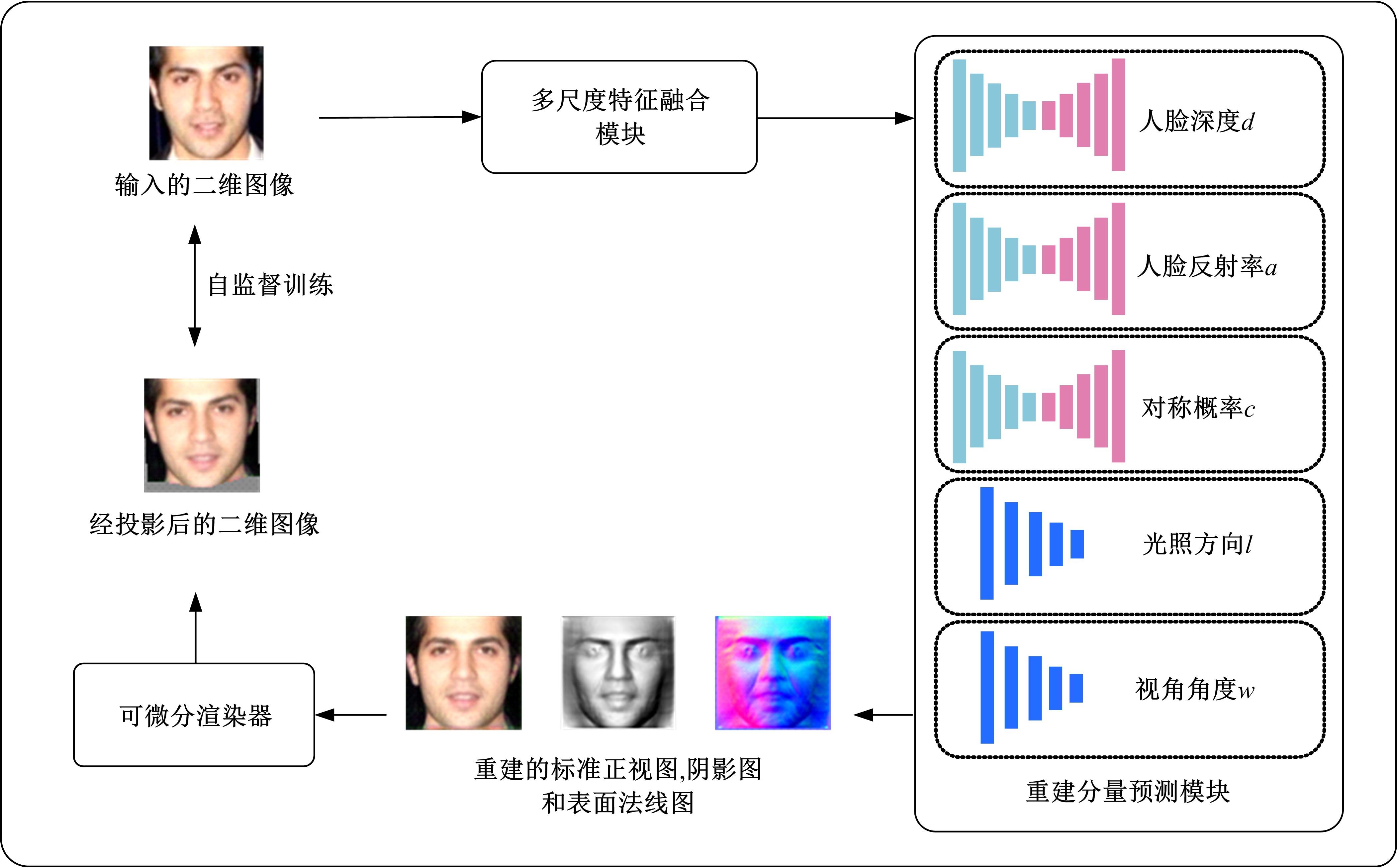
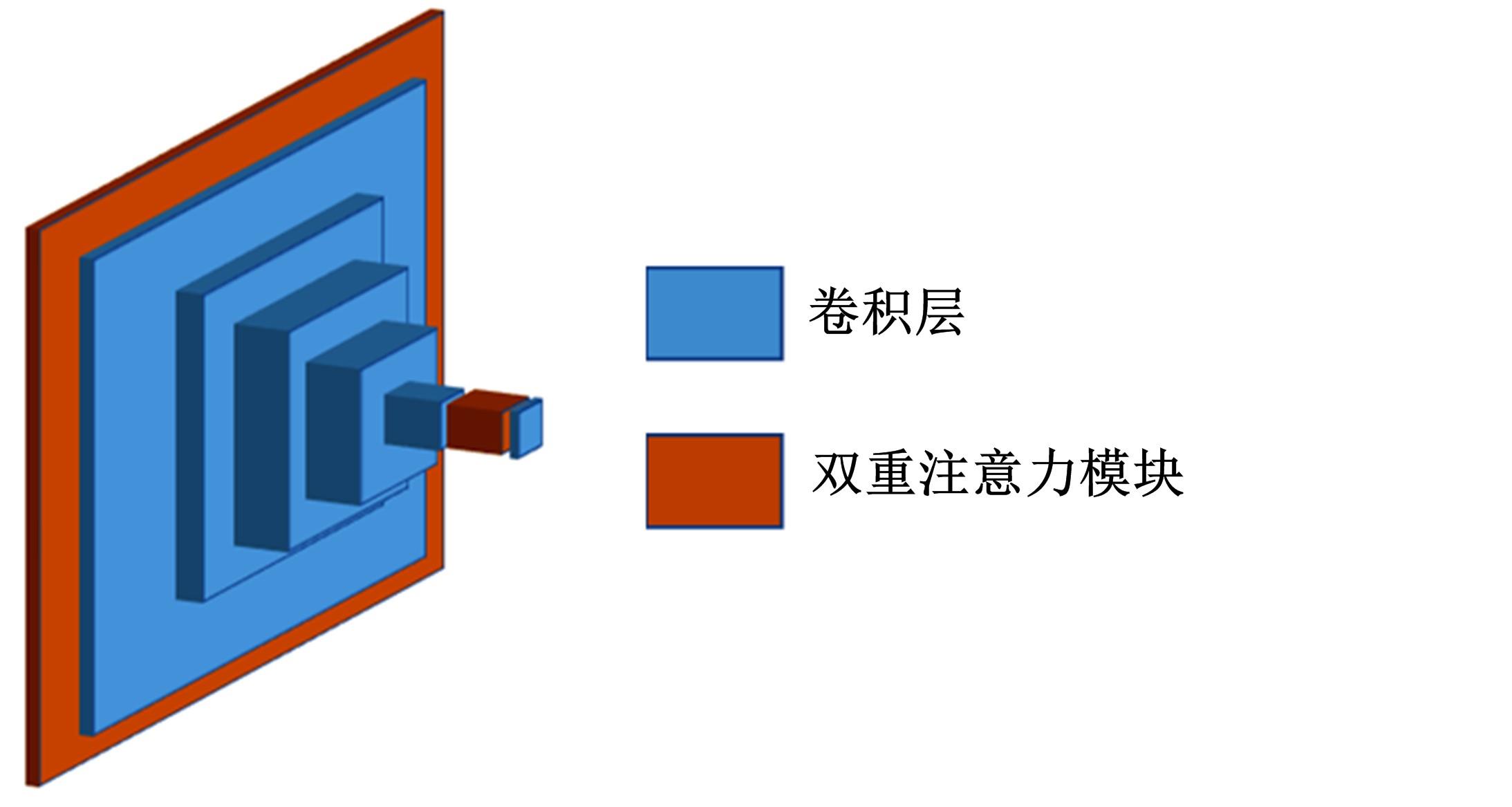
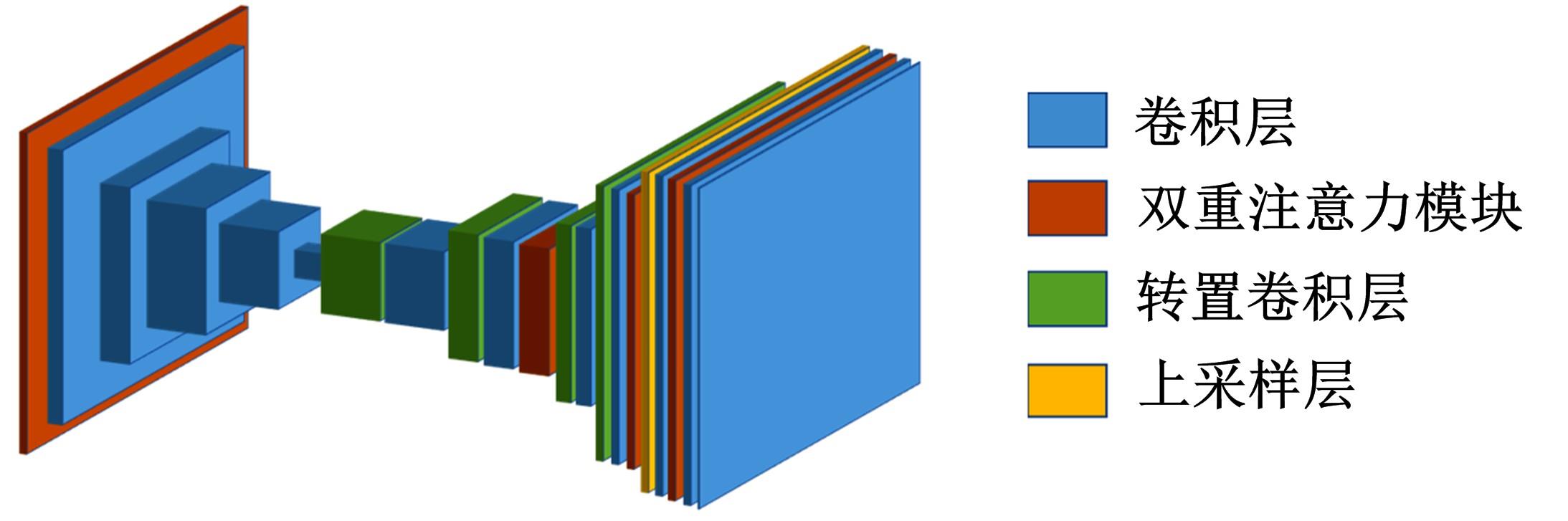
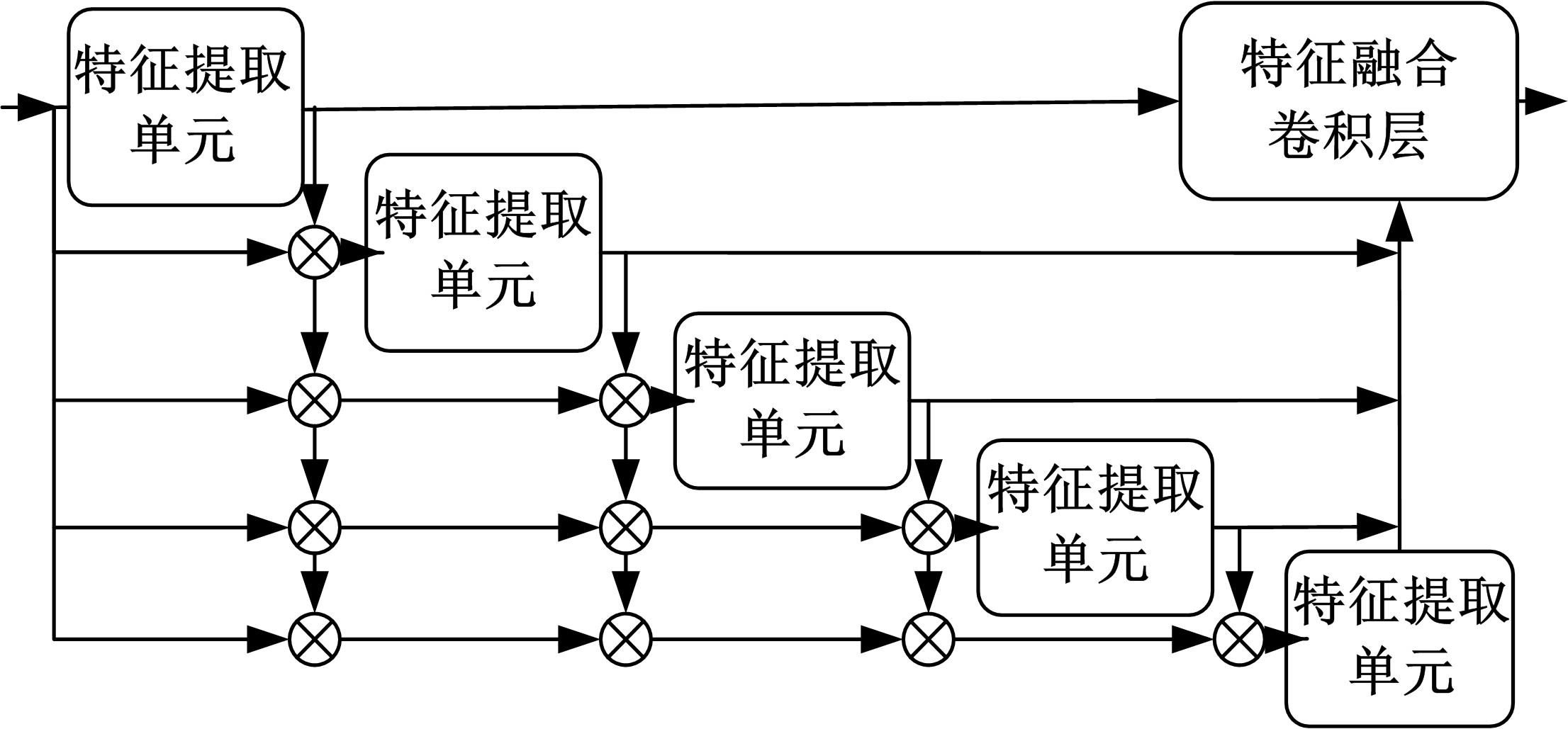
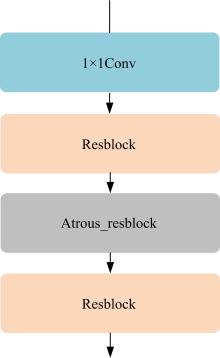
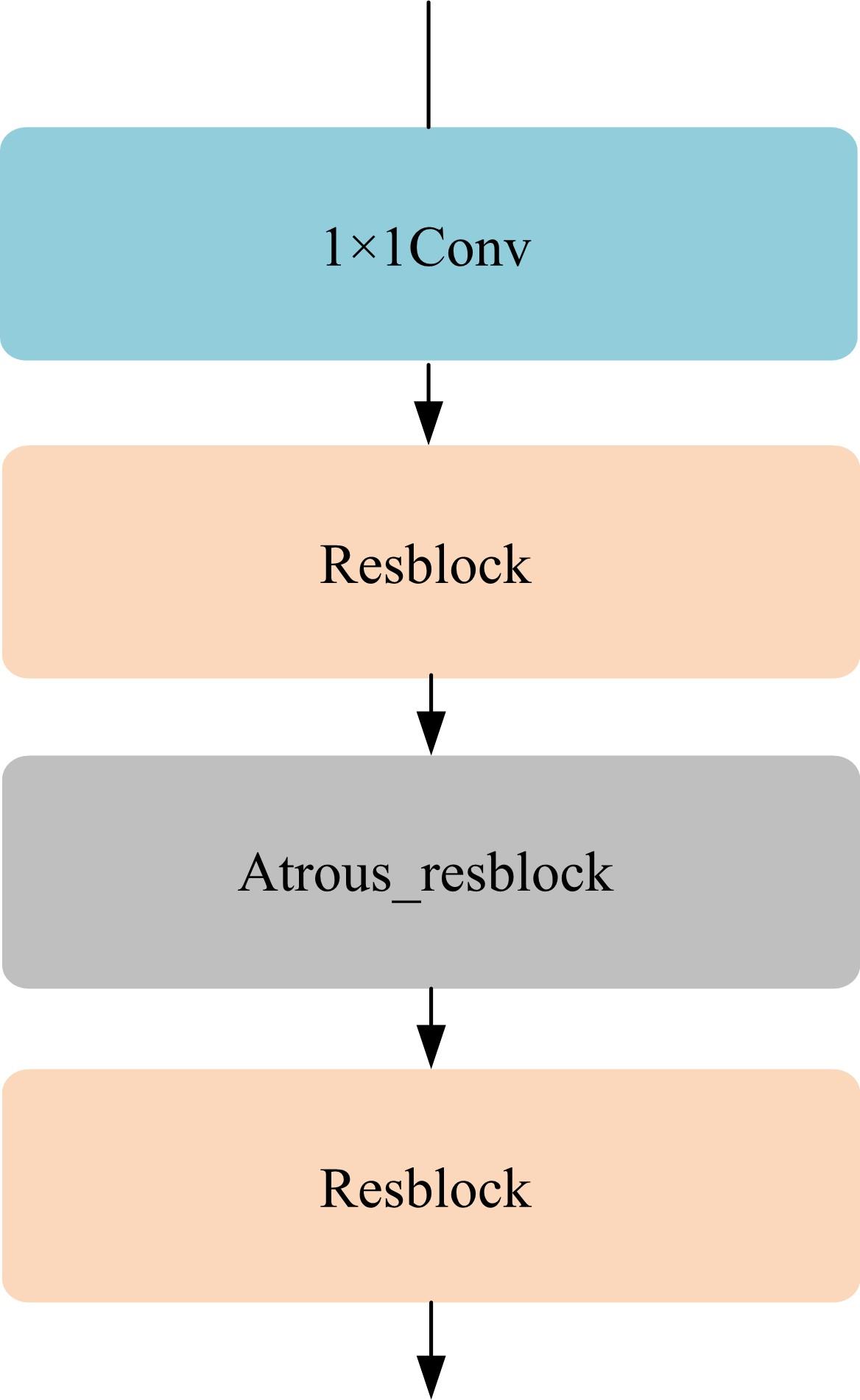
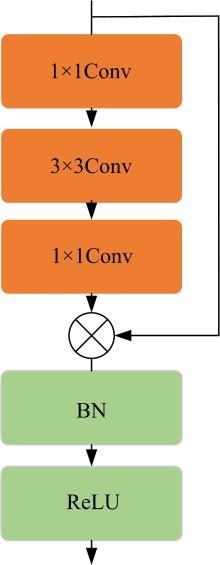
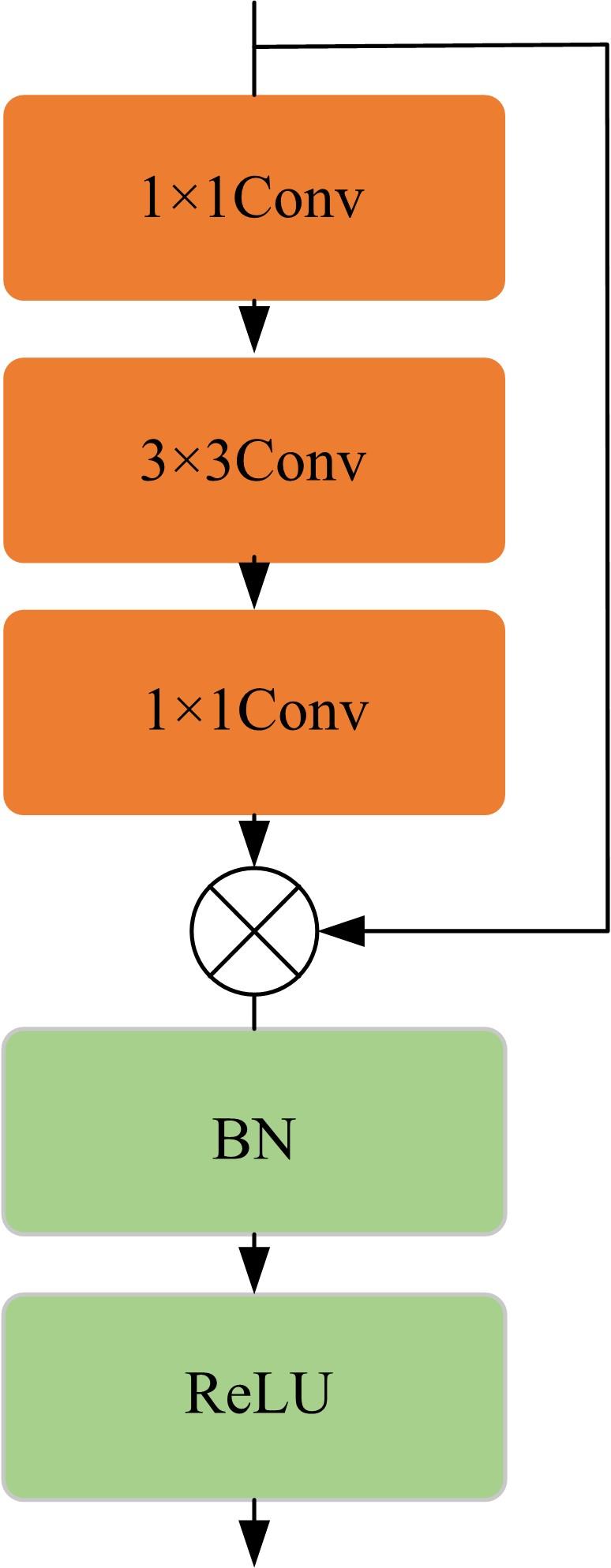
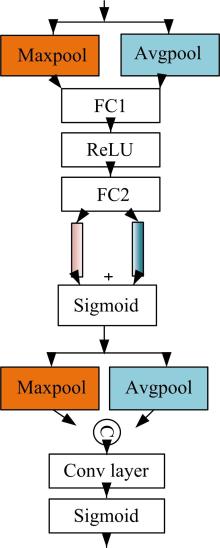
针对三维人脸重建算法的精度不足和三维人脸标注样本数量较少的问题,引入了多尺度特征提取融合模块和双重注意力机制模块,提出了一种以单幅人脸图像作为输入、利用编解码网络预测重建分量的自监督三维人脸重建算法。引入的多尺度特征提取融合模块有助于获取更丰富的多尺度人脸特征信息,编解码网络中引入双重注意力机制模块,进一步提升网络的特征提取能力,同时单幅图像输入的自监督方法绕开了传统方法中对于数据集的高要求。在BFM、Photoface和CelebA人脸数据集上进行了对比实验和消融实验,实验结果表明,相比于Unsup3D等代表性的人脸重建算法,本文算法在尺度不变深度误差(Scale-invariant depth error, SIDE)和平均角度偏差(Mean angle deviation, MAD)两项评价指标上,分别取得了10.3%到12.6%的性能提升;此外,该算法对输入图像的部分遮挡/缺失拥有着更好的鲁棒性。
中图分类号:
- TP391.4

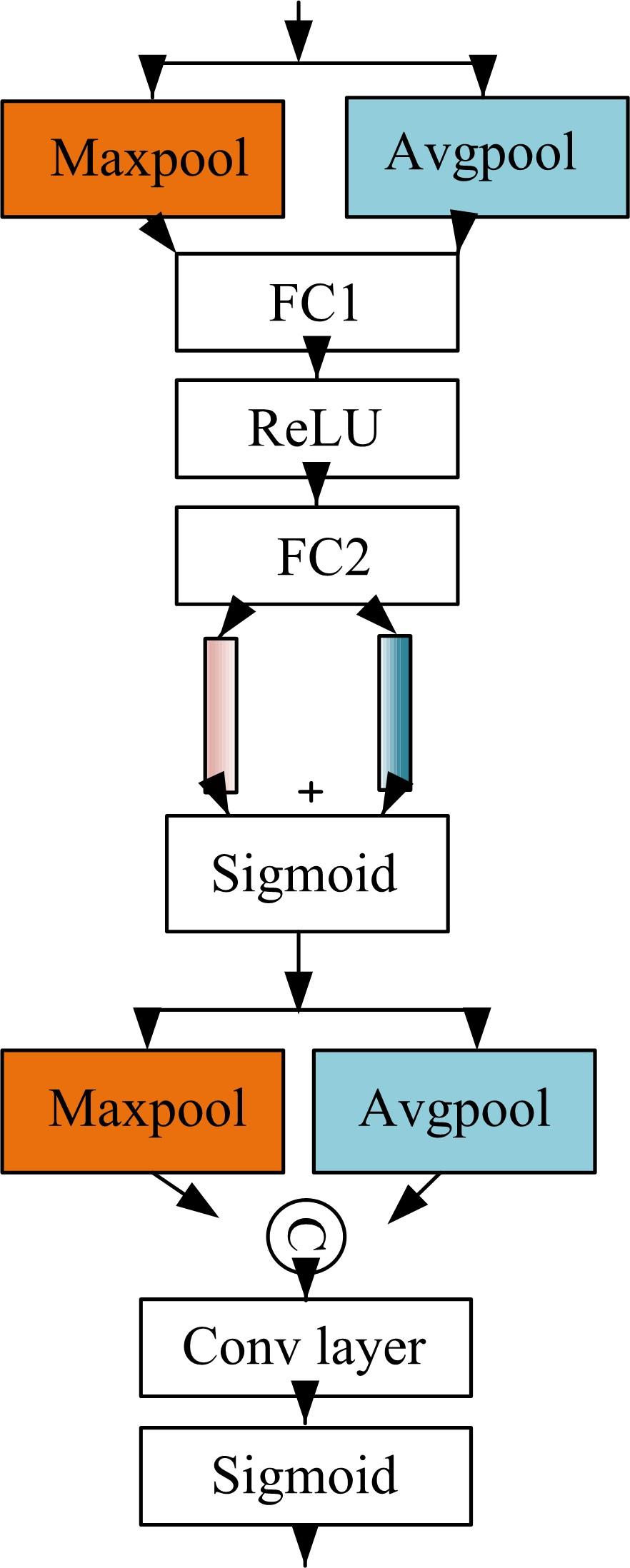




| 1 | 徐成华, 王蕴红, 谭铁牛. 三维人脸建模与应用[J]. 中国图象图形学报, 2004, 9(8): 893-903. |
| Xu Cheng-hua, Wang Yun-hong, Tan Tie-niu. Overview of research on 3D face modeling[J]. Journal of Image and Graphics, 2004, 9(8): 893-903. | |
| 2 | 王琨, 郑南宁. 基于SFM算法的三维人脸模型重建[J]. 计算机学报, 2005, 28(6): 1048-1053. |
| Wang Kun, Zheng Nan-ning. 3D face modeling based on SFM algorithm[J]. Chinese Journal of Computers, 2005, 28(6): 1048-1053. | |
| 3 | Zhu Wen-bin, Wu Hsiang-tao, Chen Ze-yu, et al. Reda: reinforced differentiable attribute for 3D face reconstruction[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4958-4967. |
| 4 | Zhu Xiang-yu, Lei Zhen, Liu Xiao-ming, et al. Face alignment across large poses: a 3D solution[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 146-155. |
| 5 | Richardson E, Sela M, Or-El R, et al. Learning detailed face reconstruction from a single image[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1259-1268. |
| 6 | Blanz V, Vetter T. A morphable model for the synthesis of 3D faces [C]∥Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, New York, USA, 1999: 187-194. |
| 7 | Booth J, Roussos A, Ponniah A, et al. Large scale 3D morphable models[J]. International Journal of Computer Vision, 2018, 126(2): 233-254. |
| 8 | Tran L, Liu Xiao-ming. On learning 3D face morphable model from in-the-wild images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(1): 157-171. |
| 9 | Cao Chen, Weng Yan-lin, Zhou Shun, et al. Facewarehouse: a 3D facial expression database for visual computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 20(3): 413-425. |
| 10 | Tuan Tran A, Hassner T, Masi I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5163-5172. |
| 11 | Chang F J, Tran A T, Hassner T, et al. Expnet: Landmark-free, deep, 3D facial expressions[C]∥The 13th IEEE International Conference on Automatic Face and Gesture Recognition, Xi'an, China, 2018: 122-129. |
| 12 | Chang F J, Tuan Tran A, Hassner T, et al. Faceposenet: making a case for landmark-free face alignment[C]∥Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 2017: 1599-1608. |
| 13 | Gecer B, Ploumpis S, Kotsia I, et al. Ganfit: generative adversarial network fitting for high fidelity 3d face reconstruction[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1155-1164. |
| 14 | Jackson A S, Bulat A, Argyriou V, et al. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1031-1039. |
| 15 | Feng Yao, Wu Fan, Shao Xiao-hu, et al. Joint 3d face reconstruction and dense alignment with position map regression network[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 534-551. |
| 16 | Tewari A, Zollhofer M, Kim H, et al. Mofa: model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]∥Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 2017: 1274-1283. |
| 17 | Sanyal S, Bolkart T, Feng Hai-wen, et al. Learning to regress 3D face shape and expression from an image without 3D supervision[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7763-7772. |
| 18 | Tu Xiao-guang, Zhao Jian, Xie Mei, et al. 3D face reconstruction from a single image assisted by 2d face images in the wild[J]. IEEE Transactions on Multimedia, 2020, 23: 1160-1172. |
| 19 | Wu S Z, Rupprecht C, Vedaldi A. Unsupervised learning of probably symmetric deformable 3d objects from images in the wild[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1-10. |
| 20 | Gao Yuan, Yuille A L. Exploiting symmetry and/or manhattan properties for 3d object structure estimation from single and multiple images[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA,2017:7408-7417. |
| 21 | Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation[C]∥International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 2015: 234-241. |
| 22 | Zhang Ruo, Tsai P S, Cryer J E, et al. Shape-from-shading: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 690-706. |
| 23 | Kato H, Ushiku Y, Harada T. Neural 3D mesh renderer[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3907-3916. |
| 24 | Yang Mao-ke, Yu Kun, Zhang Chi, et al. Denseaspp for semantic segmentation in street scenes[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3684-3692. |
| 25 | Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 3-19. |
| 26 | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [J]. arXiv preprint arXiv:, 2014. |
| 27 | Liu Zi-wei, Luo Ping, Wang Xiao-gang, et al. Deep learning face attributes in the wild[C]∥Proceedings of the IEEE International Conference on Computer Vision,Santiago, Chile, 2015: 3730-3738. |
| 28 | Paysan P, Knothe R, Amberg B, et al. A 3D face model for pose and illumination invariant face recognition[C]∥The Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance,Genova, Italy, 2009: 296-301. |
| 29 | Zafeiriou S, Hansen M, Atkinson G, et al. The photoface database[C]∥CVPR Workshops, Colorado Springs, USA, 2011: 132-139. |
| 30 | Sengupta S, Kanazawa A, Castillo C D, et al. Sfsnet: learning shape, reflectance and illuminance of facesin the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 44(6): 6296-6305. |
| 31 | Xiao Jian-xiong, Hays J, Ehinger K A, et al. Sun database: large-scale scene recognition from abbey to zoo[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010: 3485-3492. |
| 32 | Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network[C]∥Proceedings of the 27th International Conference on Neural Information Processing Systems,Bangkok, Thailand, 2014: 2366-2374. |
| 33 | Sela M, Richardson E, Kimmel R. Unrestricted facial geometry reconstruction using image-to-image translation[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1576-1585. |
| 34 | Tran A T, Hassner T, Masi I, et al. Extreme 3D face reconstruction: seeing through occlusions[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3935-3944. |
| 35 | Trigeorgis G, Snape P, Kokkinos I, et al. Face normal "in-the-wild" using fully convolutional networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 38-47. |
| [1] | 赵宏伟,张健荣,朱隽平,李海. 基于对比自监督学习的图像分类框架[J]. 吉林大学学报(工学版), 2022, 52(8): 1850-1856. |
| [2] | 马永杰,陈敏. 基于卡尔曼滤波预测策略的动态多目标优化算法[J]. 吉林大学学报(工学版), 2022, 52(6): 1442-1458. |
| [3] | 欧阳继红,郭泽琪,刘思光. 糖尿病视网膜病变分期双分支混合注意力决策网络[J]. 吉林大学学报(工学版), 2022, 52(3): 648-656. |
| [4] | 李先通,全威,王华,孙鹏程,安鹏进,满永兴. 基于时空特征深度学习模型的路径行程时间预测[J]. 吉林大学学报(工学版), 2022, 52(3): 557-563. |
| [5] | 毛琳,任凤至,杨大伟,张汝波. 双向特征金字塔全景分割网络[J]. 吉林大学学报(工学版), 2022, 52(3): 657-665. |
| [6] | 陈晓雷,孙永峰,李策,林冬梅. 基于卷积神经网络和双向长短期记忆的稳定抗噪声滚动轴承故障诊断[J]. 吉林大学学报(工学版), 2022, 52(2): 296-309. |
| [7] | 潘晓英,魏德,赵逸喆. 基于Mask R⁃CNN和上下文卷积神经网络的肺结节检测[J]. 吉林大学学报(工学版), 2022, 52(10): 2419-2427. |
| [8] | 赵宏伟,霍东升,王洁,李晓宁. 基于显著性检测的害虫图像分类[J]. 吉林大学学报(工学版), 2021, 51(6): 2174-2181. |
| [9] | 王德兴,吴若有,袁红春,宫鹏,王越. 基于多尺度注意力融合和卷积神经网络的水下图像恢复[J]. 吉林大学学报(工学版), 2021, 51(4): 1396-1404. |
| [10] | 赵亚慧,杨飞扬,张振国,崔荣一. 基于强化学习和注意力机制的朝鲜语文本结构发现[J]. 吉林大学学报(工学版), 2021, 51(4): 1387-1395. |
| [11] | 徐卓君,杨雯婷,杨承志,田彦涛,王晓军. 雷达脉内调制识别的改进残差神经网络算法[J]. 吉林大学学报(工学版), 2021, 51(4): 1454-1460. |
| [12] | 刘元宁,吴迪,朱晓冬,张齐贤,李双双,郭书君,王超. 基于YOLOv3改进的用户界面组件检测算法[J]. 吉林大学学报(工学版), 2021, 51(3): 1026-1033. |
| [13] | 刘富,刘璐,侯涛,刘云. 基于优化MSR的夜间道路图像增强方法[J]. 吉林大学学报(工学版), 2021, 51(1): 323-330. |
| [14] | 赵海英,周伟,侯小刚,张小利. 基于多任务学习的传统服饰图像双层标注[J]. 吉林大学学报(工学版), 2021, 51(1): 293-302. |
| [15] | 赵宏伟,刘晓涵,张媛,范丽丽,龙曼丽,臧雪柏. 基于关键点注意力和通道注意力的服装分类算法[J]. 吉林大学学报(工学版), 2020, 50(5): 1765-1770. |
|
||